

La verificación de identidad remota es imposible sin una captura de imagen adecuada. Pero volver a tomar la imagen para cumplir con los requisitos—establecidos para su seguridad, por cierto—sigue siendo muy molesto. Resolver ese problema es uno de los principales propósitos de usar redes neuronales en aplicaciones móviles.
Suscríbase para recibir un resumen quincenal del blog de Regula
Por qué no se puede simplemente agregar redes neuronales a una aplicación
En la verificación de identidad, las redes neuronales le permiten evaluar (o incluso mejorar) la calidad de las imágenes en el momento, en lugar de enviar datos de ida y vuelta desde el dispositivo al servidor y de regreso. En otras palabras, hacen que el proceso de captura sea realmente inteligente. Sin embargo, esa funcionalidad tiene un costo: las redes neuronales aumentan el tamaño de una aplicación.
Supongamos que usted desea implementar tecnología de reconocimiento facial. Un usuario abre la aplicación, se toma una selfie y — listo — obtiene aprobación para acceder a un producto o servicio. Sin embargo, detrás de escena, esta tarea requiere numerosas redes neuronales. La detección facial rápida, el reconocimiento y la verificación de calidad del rostro del ejemplo anterior podrían requerir alrededor de 20 redes neuronales. La cifra puede ser incluso mayor, ya que el proceso requiere revisar y validar múltiples parámetros.
En el mejor de los casos, cada una de estas redes pesa alrededor de dos megabytes. Una simple multiplicación muestra que, en este caso, usted necesitará alrededor de 40 megabytes de memoria del smartphone dedicados solo a almacenar las redes neuronales de una sola aplicación.
Al mismo tiempo, casi no hay personas que usen solo una aplicación en su smartphone. Por ejemplo, un usuario promedio en Estados Unidos interactúa con más de 46 aplicaciones al mes.
Sin embargo, no se trata solo de las limitaciones técnicas de los dispositivos. Las aplicaciones pesadas — tanto móviles como web — tienden a cargar más lento, perjudicando la experiencia del usuario desde el inicio. Si a eso se suma una conexión a internet inestable, usted verá una caída drástica en las conversiones y un aumento en la tasa de abandono.
Por eso, los desarrolladores dedican mucho esfuerzo a hacer que las redes neuronales (y las aplicaciones en general) sean más pequeñas, pero igualmente eficaces.
Por qué las redes neuronales son enormes
Para empezar, ¿qué tan grande es “grande”? GPT-3, la versión ya desactualizada de un modelo de red neuronal para crear todo tipo de texto, tenía más de 175 mil millones de parámetros de aprendizaje automático y requería 800 gigabytes para almacenarse. Aunque OpenAI, sus desarrolladores, no dirá cuánto más grande es el GPT-4 de nueva generación, existen testimonios de que el modelo de lenguaje más reciente tiene 1 billón de parámetros.
El ejemplo anterior ciertamente es un caso extremo. Las redes que pueden resultar útiles para la verificación de identidad no son tan enormes. Por ejemplo, CRAFT, que es un modelo avanzado de detección de texto, ocupa alrededor de 100 MB de espacio. Sin embargo, eso sigue siendo demasiado para una aplicación.
Entonces, ¿por qué las redes neuronales son tan grandes? La respuesta está en el proceso de entrenamiento que les permite cumplir adecuadamente sus funciones. En términos simples, un operador alimenta la red con grandes cantidades de datos de ejemplo.
Aunque no existe una regla fija sobre el tamaño mínimo del conjunto de datos de entrenamiento, la “regla de diez veces” se usa a menudo como punto de partida. Si, por ejemplo, un algoritmo reconoce documentos de identidad con base en 1.000 parámetros, usted necesita al menos 10.000 imágenes diversas de documentos para entrenar el modelo. El reconocimiento facial puede requerir aún más muestras: para comprobar la identidad de alguien mediante comprobación de los rostros, una red neuronal debe aprender a diferenciar millones de rostros humanos.
La idea detrás del proceso es simple: cuanto mayor sea el número de parámetros en una red neuronal, mejor será su desempeño. Lamentablemente, esto es un arma de doble filo, ya que más parámetros a la vez ralentizan la inferencia — la entrega del resultado — e incrementan los costos computacionales.
Al igual que en un cerebro humano, una red neuronal incluye conexiones neuronales tanto necesarias como redundantes después de ser entrenada. Estas últimas o bien no se usan en absoluto, o duplican conexiones activas. Sin embargo, las conexiones redundantes no desaparecen: permanecen en lo profundo de la red, sumando a su tamaño total.
Incorporar todas esas capacidades de redes neuronales en el almacenamiento limitado de un smartphone es todo un desafío, pero las técnicas de compresión de redes neuronales vienen al rescate.
Métodos de compresión de redes neuronales
Una vez que una red neuronal está correctamente entrenada, la siguiente etapa consiste en encontrar el equilibrio adecuado entre eficiencia y tamaño. Es una tarea crucial, ya que muchos sistemas en los que se implementará una red neuronal tienen límites de memoria. La lista incluye no solo plataformas móviles, ya que las soluciones web también son sensibles a la memoria.
Existen varios métodos de compresión de redes neuronales que abordan dos parámetros clave: el tiempo de entrenamiento de la red y el tiempo de inferencia. A continuación, profundizaremos en tres de ellos que se utilizan en las soluciones de Regula para verificación de identidad.
Poda de pesos
La poda es un método de compresión de redes neuronales que se utiliza para recortar parámetros redundantes (pesos) y eliminar todas las conexiones excesivas que la red almacena internamente. A medida que se eliminan sesgos, el tamaño de la red neuronal se reduce y comienza a responder más rápido. Como resultado, usted obtiene una red neuronal precisa que ocupa solo la memoria del dispositivo necesaria para funcionar correctamente.
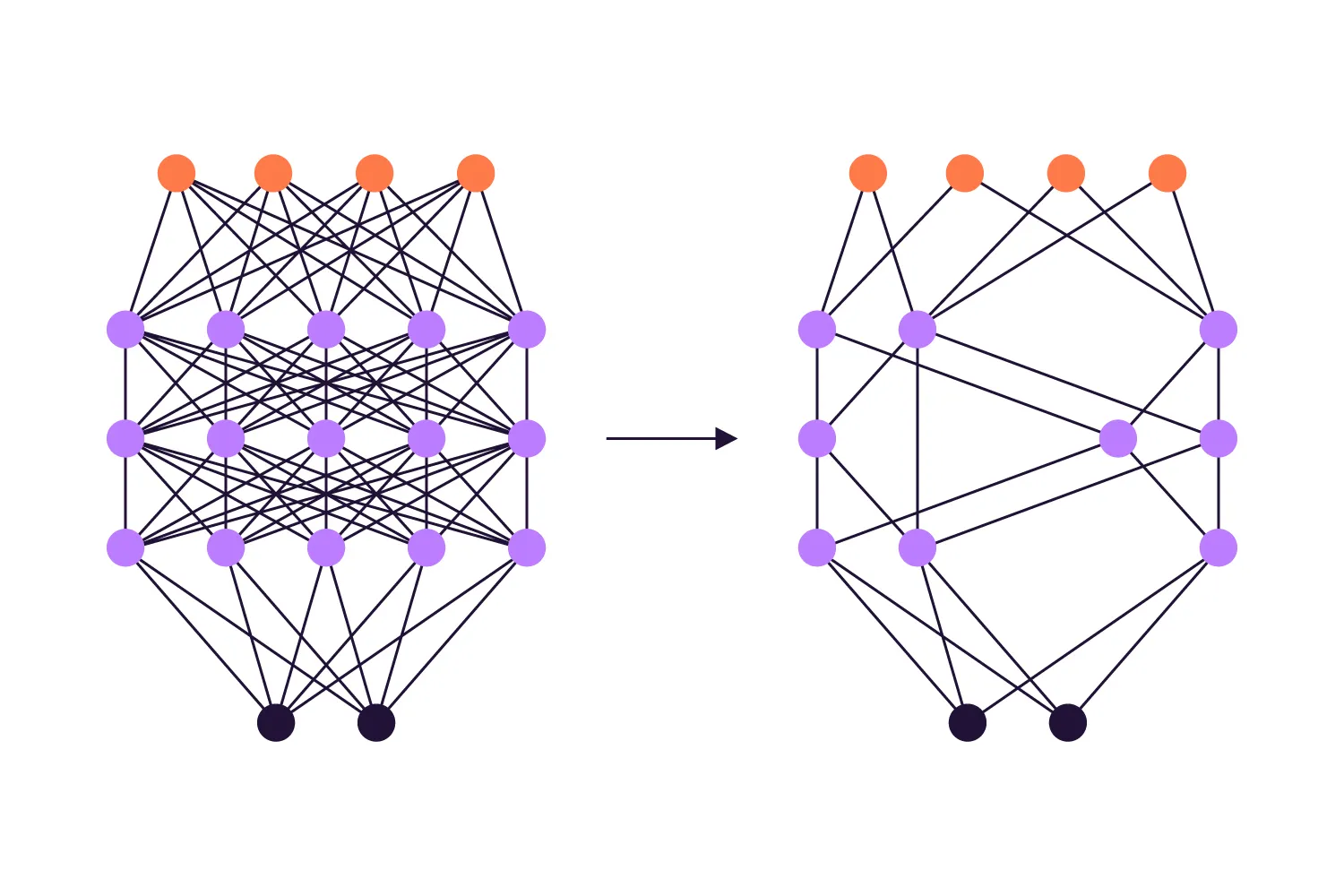
El procedimiento de poda de pesos parece ser prácticamente lo opuesto a lo que ocurrió en la etapa de entrenamiento. Aun así, usted no quiere que la red pierda todo lo que aprendió. Por eso se aplica el concepto de “daño cerebral óptimo”. Según este concepto, se debe eliminar lo máximo posible, pero detenerse justo antes de que el rendimiento empiece a verse afectado.
El método implica numerosas iteraciones:
Entrenar la red
Estimar la importancia de cada peso
Eliminar el peso de baja importancia
Comparar el resultado con el inicial mediante un ciclo de retroalimentación
Reentrenar la red
Volver al paso 2
Por muy bien que suene, la poda por sí sola todavía no es suficiente para que cualquier red neuronal se adapte fácilmente a cualquier plataforma, incluidas las móviles. Por eso, en Regula detenemos la poda de nuestras redes neuronales cuando su capacidad y velocidad son las más altas posibles, independientemente del tamaño que tengan en ese momento, y pasamos a la siguiente etapa.
Cuantización
La cuantización de redes neuronales es, técnicamente, un proceso para reducir la precisión de los pesos de la red, por ejemplo, reemplazando números de punto flotante (como 1,3333…) por enteros (133/100). El objetivo es disminuir la variación de los pesos en la red, que por lo general es bastante alta, y hacer que sean más similares entre sí.
La lógica de “hacerlos más similares” proviene de los algoritmos de compresión: cuanto menor sea la variación de los datos en un archivo, mayor será la tasa de compresión. Un archivo de texto que contenga solo una letra repetida se comprimirá con una tasa mayor que un archivo que contenga letras variadas. El mismo principio aplica a la compresión de redes neuronales, donde pesos más homogéneos permiten una compresión más eficiente.
Para hacer la cuantización aún más efectiva, agrupamos pesos similares en clústeres. Esta agrupación en clústeres conduce a una reducción significativa de la entropía. Como resultado, una red neuronal puede comprimirse de manera eficaz incluso con un compresor estándar.
Sin embargo, con la cuantización, es relativamente fácil perder la precisión de una red. Por lo tanto, en la mayoría de los casos, es una especie de equilibrio entre calidad y tamaño. Pero no para Regula.
El ingrediente secreto: métodos internos únicos de cuantización de Regula
La industria de la IA sabe que una compresión de cuatro o cinco veces — por lo general de 32 a 8 bits por peso —mediante cuantización no afecta de manera significativa la precisión y la calidad de las redes neuronales. Sin embargo, incluso una red neuronal comprimida cinco veces no se ajustará a una solución móvil, al menos para verificación de identidad, ya que requiere decenas de redes neuronales para operar.
En algunos casos, ahí terminaría la historia. Sin embargo, los ingenieros de Regula desarrollaron métodos internos únicos de cuantización que hacen posible una compresión de 10 y 14 veces sin comprometer la calidad. Por ejemplo, la red neuronal que funciona como detector de rostros en las soluciones de Regula puede comprimirse entre 10 y 12 veces. La red para comprobar los hologramas puede reducirse entre 12 y 14 veces en tamaño.
Y ese ni siquiera es el límite.
Para algunas redes neuronales, los expertos de la empresa han logrado alcanzar un grado de compresión de 23x a 32x. Eso significa que cada peso en una red — por lo general hay millones de pesos en cada red neuronal que utiliza Regula — puede reducirse de 32 bits (el máximo) a 1 bit (el mínimo).
Gracias a estos avances, los SDK de Regula para verificación de documentos y biometría pueden integrarse en una aplicación móvil y/o web sin inflar su tamaño. Además, a medida que surgen nuevas tareas, se pueden agregar nuevas redes. Esto es posible gracias a la capacidad de comprimirlas muchas veces sin perder precisión ni velocidad, y sin generar un impacto perceptible en la memoria del dispositivo o del sistema.
Para resumir
En el ámbito de la verificación de identidad, todas las tareas principales, como el reconocimiento de documentos o biometría, la verificación contra parámetros específicos, las comprobaciones de prueba de vida y más, se realizan mediante redes neuronales. Gracias a esto, las operaciones de verificación toman segundos, son precisas y le permiten reducir costos operativos.
Aun así, incorporar redes neuronales en soluciones móviles o embebidas sin sacrificar calidad siempre es un desafío de ingeniería. Afortunadamente, es un desafío que los ingenieros de Regula lograron resolver de manera bastante elegante. Si usted enfrenta la tarea de implementar una verificación de identidad eficaz en su aplicación, con gusto le ayudaremos.



