

En el pasado, la mayor parte del procesamiento de imágenes se hacía mediante algoritmos estándar. Las redes neuronales son como las tareas de procesamiento de imágenes que antes realizaban los algoritmos estándar, pero potenciadas al máximo. La velocidad aumentó de forma enorme e hizo que cosas que antes se consideraban imposibles… bueno, fueran posibles.
A pesar de su impacto cada vez mayor, muchas personas aún no saben qué son las redes neuronales y cómo funcionan. En esta publicación, le guiaremos a través de los conceptos básicos y veremos cómo se utilizan en el campo de la verificación de identidad.
Comencemos.
Suscríbase para recibir un resumen quincenal del blog de Regula
¿Qué es una red neuronal?
Una red neuronal es un algoritmo informático inspirado en la estructura del cerebro humano. Analiza grandes cantidades de datos para encontrar patrones, aprender de ellos y luego aplicar lo aprendido para predecir el resultado para consultas similares.
En la práctica, estas consultas pueden ser casi cualquier cosa: desde responder preguntas e identificar objetos hasta traducción en tiempo real, o incluso crear arte digital.
Una red neuronal consta de capas de nodos interconectados (“neuronas”) que procesan información en paralelo. La primera capa se llama capa de entrada, y la última se llama capa de salida. Las capas intermedias se llaman ocultas, aunque realizan la mayor parte del cálculo.
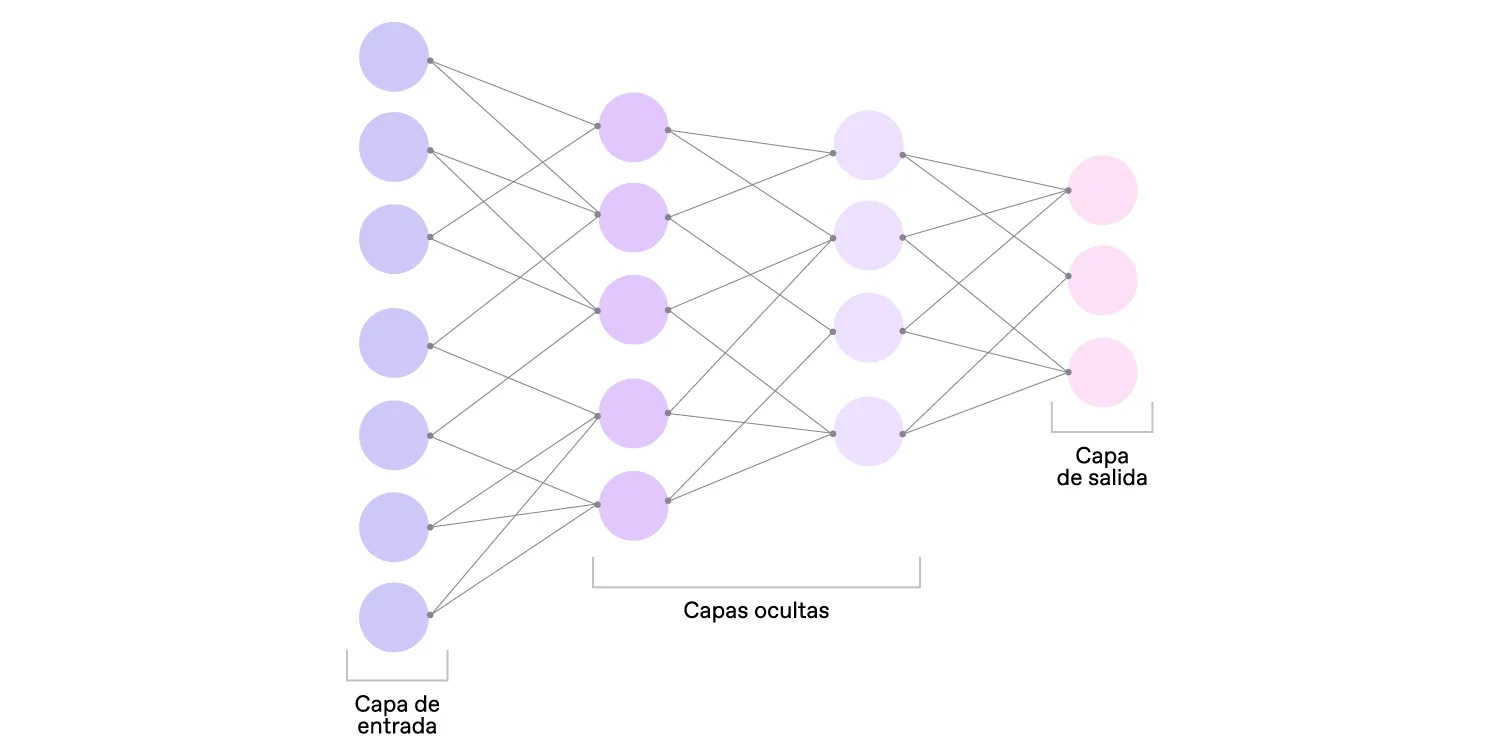
Los nodos de una capa están conectados con los nodos de la siguiente capa mediante conexiones. Eso significa que puede haber varios otros nodos de los que reciben datos y varios nodos a los que transmiten esos datos.
A cada una de las conexiones se le asigna un valor, o “peso”. Cuando la red recibe un dato, los nodos reciben un valor diferente a través de cada una de sus conexiones y lo multiplican por el peso asociado. Luego suman los resultados y pasan el valor por la función de activación.
La activación es una evaluación matemática para decidir si la entrada del nodo en la red es importante o no. Si el valor resultante supera el valor umbral, este nodo en particular “se activa”, lo que significa que transmitirá los datos a la siguiente capa.
La capa final es, en esencia, nuestro resultado.
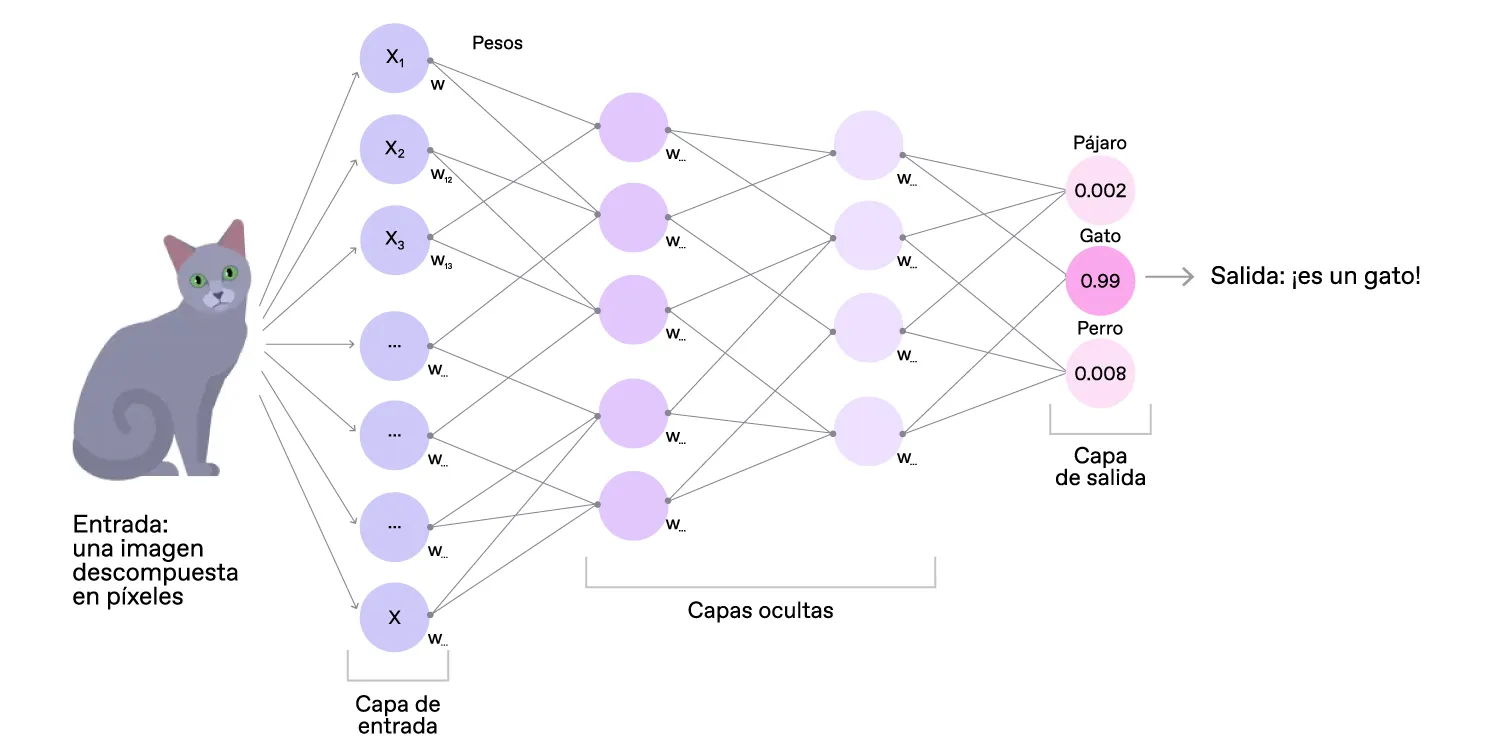
Dependiendo del modelo, podríamos necesitar realizar operaciones adicionales — una función de activación especial — con la capa de salida para obtener el resultado en un formato más fácil de interpretar. Por ejemplo, en un modelo de clasificación (hablaremos de las aplicaciones de las redes neuronales más adelante), el nodo con el valor más alto en la capa de salida determina cómo se clasifica el objeto de entrada.
The types of neural networks
Existen dos tipos de redes neuronales según la dirección en la que pueden transmitir las señales.
Si los datos fluyen en una sola dirección, dichas redes se denominan “feed-forward”. En su forma básica, es la variante más simple de redes neuronales, pero sus iteraciones pueden ser muy avanzadas.
Por ejemplo, uno de los modelos más populares utilizados hoy en día son las redes neuronales convolucionales (CNN), que también tienen una arquitectura feed-forward. Las CNN son esenciales para diversas tareas de visión por computadora, como el reconocimiento y la clasificación de imágenes, incluido el reconocimiento facial.
Si los datos viajan en ambas direcciones, se trata de una red neuronal “feed-back”. Un ejemplo de esta arquitectura son las redes neuronales recurrentes (RNN), donde los datos pueden formar un bucle: desde la entrada a través de las capas hasta la salida, y luego la salida se utiliza como entrada nuevamente. Dichas redes pueden utilizarse, por ejemplo, para el procesamiento de lenguaje natural.
Cómo se entrenan las redes neuronales
Como dijimos anteriormente, las redes neuronales aprenden a realizar tareas al analizar muestras de datos de entrenamiento. Estas muestras generalmente están etiquetadas manualmente. Así, por ejemplo, a una red de reconocimiento de objetos se le pueden proporcionar miles de imágenes etiquetadas de gatos y perros para encontrar características específicas de cada animal y asociarlas de manera consistente con las etiquetas correspondientes.
Inicialmente, los pesos y el umbral de activación se establecen en valores aleatorios. Una vez que se introduce el conjunto de datos de entrenamiento y se entrega la salida, esta se compara con la entrada real para comprobar si la predicción fue verdadera o falsa. Con base en esta información, se ajustan los pesos. Después de numerosas iteraciones, la red adquiere suficiente “experiencia” para entregar una calidad y precisión aceptables.
Al principio, las redes neuronales solo eran capaces de resolver las tareas binarias más sencillas. Algo como distinguir entre círculos rojos y verdes, mientras que distinguir entre cuadrados y asteriscos ya estaba fuera de su alcance. Debido a esta falta de eficiencia, las redes neuronales se consideraron un callejón sin salida durante mucho tiempo.
Todo cambió con el inicio de la era del big data. Las personas se dieron cuenta de que las redes neuronales necesitaban enormes cantidades de datos para funcionar correctamente. Y todo estaba listo para ello: la cantidad de datos procesables en el mundo aumentó de manera tremenda y el hardware para manejarlo también estaba al alcance.
Hay una afirmación popular que circula por la web según la cual se necesitan alrededor de 10.000 elementos de datos para entrenar una red neuronal. Sin embargo, este número depende en gran medida de la variabilidad de los datos. Entrenar una red neuronal para distinguir círculos rojos y verdes requiere menos muestras que entrenarla para distinguir cuadrados y asteriscos. Esta última es una tarea más difícil porque los asteriscos se parecen a los cuadrados bajo ciertos ángulos. Por lo tanto, cuanto mayor sea la variación en la entrada, más datos se requieren para el entrenamiento.
Eso es en un mundo ideal.
Con bastante frecuencia, existe un déficit de datos de entrada. Pero incluso en esa situación, sigue siendo posible entrenar una red neuronal con la ayuda de técnicas de aumento de datos. Estas técnicas le permiten generar muchos elementos similares a partir de una sola muestra. Entrenada con estos elementos, su red puede salir al mundo real, comenzar a recopilar datos reales y luego mejorar la calidad de la salida directamente durante el proceso.
Al mismo tiempo, no siempre es necesario empezar desde cero. El proceso de entrenamiento de redes neuronales a menudo implica ingeniería inversa, en la que se toma una red neuronal grande y se comienza a recortarla hasta obtener una más pequeña. El propósito es reducir el tamaño de la red mientras se preserva la calidad de la salida. Cuando el rendimiento comienza a degradarse durante el recorte, se detiene el procedimiento. A esto se le llama “daño cerebral óptimo”.
El daño cerebral óptimo es el concepto que sustenta los métodos de compresión de redes neuronales. La compresión es crucial para adaptar una red a un dispositivo que tiene limitaciones de almacenamiento, como un teléfono inteligente. Además, cuanto más pequeña es la red, más rápido funciona y menos batería consume.
Ahora que por fin hemos cubierto los conceptos básicos, veamos cómo se aplican las redes neuronales en la verificación de identidad.
Cómo se utilizan las redes neuronales para la verificación de identidad
Es una tarea difícil dar una lista fija de tipos de redes neuronales, ya que siguen surgiendo nuevos tipos con el desarrollo de la IA y el aprendizaje automático. En el campo de la verificación de identidad, utilizamos cuatro modelos principales:
Detección,
Segmentación,
Clasificación,
y Regresión.
1. Detección
Un modelo clásico de detección toma una imagen como entrada y genera áreas rectangulares y la probabilidad (confianza) con la que se puede encontrar el objeto en esa área. También puede identificar si hay múltiples objetos dentro del encuadre.
El objeto puede ser cualquier cosa: un documento de identidad, el rostro de alguien o elementos dentro de un documento, como una firma, un holograma o simplemente un campo de texto. Si es esto último, las cadenas de texto detectadas pueden luego pasarse al reconocimiento óptico de caracteres (OCR).
Opcionalmente, Usted también puede entrenar la red para entregar información adicional, como el ángulo de rotación del objeto detectado, puntos de referencia faciales, etc.

¡Detectado! El documento está en algún lugar dentro del rectángulo rojo.
2. Segmentación
Lo que hace un modelo de segmentación es, básicamente, una clasificación de píxeles en una imagen de entrada. Etiqueta cada píxel con una clase específica, lo que le permite obtener información más detallada sobre la imagen.
Al ser una extensión lógica del modelo de detección descrito anteriormente, la segmentación puede ayudarle a conocer la forma exacta de un objeto detectado, ajustar con mayor precisión sus bordes y determinar qué píxel pertenece a qué elemento. Para una tarjeta de identidad como objeto en nuestro ejemplo, las clases serán:
el documento,
los bordes,
las esquinas,
y el fondo.

Así es como una red neuronal de segmentación “ve” la posición exacta del documento.
Una vez que los modelos de detección y segmentación han completado sus tareas, entran en juego algoritmos simples de transformación para mayor conveniencia. Estos algoritmos pueden corregir la inclinación de objetos fotografiados en ángulo antes de pasarlos para un procesamiento adicional. Esto suele ser útil para la verificación de identidad remota, donde Usted necesita depender de la habilidad de los usuarios al tomar fotos de sus documentos.

La red neuronal convirtió una imagen de un documento a una vista estándar que es conveniente para trabajar.
3. Clasificación
En el modelo de segmentación anterior, la red asigna una clase a cada píxel de una imagen de entrada. Sin embargo, suponga que Usted quiere saber qué objeto hay en general. En ese caso, necesita asignar una clase al objeto en su conjunto. Este modelo se conoce como clasificación.
La clasificación nos indica el grado en que un objeto de entrada pertenece a cada una de las clases. Por ejemplo, una red de clasificación de tipo de documento entrega las clases principales — tipos de documentos — a las que este objeto pertenece con la mayor probabilidad. En nuestro caso, es una tarjeta de identidad letona, no una licencia de conducir de Utah.
Los modelos de clasificación siempre deben tener un número determinado de clases predefinidas por un ingeniero con anticipación. Por ejemplo, las clases para una red que distingue gatos de perros por una foto serán “gato”, “perro” y “no definido”.
Contar con esta clase “no definido” es esencial para evitar ambigüedades. Todas las salidas potenciales que esperamos obtener deben dividirse en conjuntos no superpuestos que cubran completamente los casos de uso, incluidos aquellos en los que una clasificación adecuada es imposible. De lo contrario, la red tendrá que elegir entre respuestas obviamente incorrectas.

La red neuronal clasificó este documento como una tarjeta de identidad letona, emitida en 2012.
4. Regresión
En un modelo de regresión, el objetivo es predecir el valor de salida. A diferencia de la clasificación, donde procesan los datos de entrada para asignar una clase de una lista limitada (¿Hay un rostro en la imagen? ¿De quién es? ¿Es hombre o mujer?), la regresión asigna nuevos valores, por ejemplo, estima la edad de una persona en una foto.

Una predicción bastante precisa, ya que la persona tenía 36 años en el momento en que este documento venció.
Es importante señalar que hoy en día las redes neuronales a menudo se utilizan en combinación. En Regula contamos con una navaja suiza de redes: algunas redes se usan para evaluaciones preliminares de calidad de datos, otras revisan el fondo y la iluminación para determinar si cumplen con los requisitos, y luego hay una red que verifica que los ojos estén abiertos y mirando a la cámara (si es una verificación biométrica), y otra que ejecuta una prueba de vida—solo por mencionar algunas.
Esta combinación de redes neuronales normalmente opera en segundo plano dentro de una sola aplicación para entregar un resultado final: verificación de identidad aprobada o rechazada.
Poniéndolo en práctica: Un caso de uso de la vida real
Ahora pasemos de la teoría a la práctica y veamos cómo las redes neuronales pueden utilizarse específicamente para fines de verificación de identidad. Para mayor conveniencia, utilizaremos las soluciones de Regula como ejemplo.
Suponga que un pasajero llega a un aeropuerto donde hay Control Fronterizo Automatizado (ABC) disponible. Al igual que con un proceso tradicional que involucra a un agente fronterizo, el ABC necesita asegurarse de que el documento de identidad sea válido y de que quien lo presenta sea realmente la persona cuya foto está impresa en el documento.
El pasajero coloca su documento en un lector y mira a una cámara. Aquí es donde entra un conjunto de redes neuronales entrenadas para fines de verificación de identidad.
Una vez que el lector de documentos ha escaneado el documento de identidad, varias redes neuronales diseñadas específicamente para la verificación de documentos entran en acción. Estas redes:
detectan el documento e identifican su tipo;
evalúan la presencia de características de seguridad, como MRZ, código de barras y chip RFID;
leen los datos;
realizan comprobaciones cruzadas de los datos de diferentes elementos;
realizan una comprobación de autenticidad.
Mientras el lector de documentos está funcionando, el pasajero se somete a una verificación biométrica.
Los ABC cuentan con un módulo integrado para comprobación biométrica facial. Las redes neuronales pueden, por ejemplo, garantizar que el rostro del pasajero sea claramente visible, que la persona esté mirando directamente a la cámara y que no haya obstrucciones faciales como una mascarilla o gafas de sol.
También pueden evaluar expresiones faciales, ya que para el examen biométrico facial es importante verificar que el rostro esté neutral, no sonriendo y que los ojos no estén anormalmente muy abiertos.
Una red neuronal adicional se integra en el procedimiento de comparación facial: compara la fotografía tomada en el control fronterizo con las fotos del titular en el documento de identidad, en el chip y en la visa. Si coinciden, se verifica la identidad y el pasajero puede continuar.
Las redes neuronales son clave para la verificación de identidad
Hubo tiempos en los que las personas no podían imaginar un automóvil y soñaban con caballos más rápidos. Lo mismo ocurre con la verificación de identidad. En lugar de depender de la experiencia y la intuición humanas (“caballos más rápidos”), las redes neuronales cubren de manera efectiva los procesos de procesamiento, verificación y autenticación de documentos de identidad.
La mejor parte: todas esas operaciones ocurren en segundos y sus resultados son incluso más precisos que el manejo manual.
La velocidad y la flexibilidad que proporcionan las redes neuronales son una gran ventaja para quienes aprovechan este poder. No es de extrañar que casi todos los productos del portafolio de Regula aprovechen redes neuronales para entregar resultados confiables al instante.
Ahora, nos gustaría escucharle.
¿Qué le entusiasma más acerca de las redes neuronales? ¿Sabía Usted que las redes neuronales se utilizan ampliamente para la verificación de identidad? ¿Reemplazarán a los humanos con el tiempo? No dude en compartir lo que piensa con nosotros en el grupo de LinkedIn de Regula.