

In 2025, the standards for age checks were raised to a level never seen before. Now, if a service has age-restricted content, features, or account rules, it is more and more often required to perform highly effective age verification. This means that, in many cases, a plain birth year field will not do the job anymore.
But what will? What kind of age verification will be sufficient in 2026 and onwards? What sources should one consult when choosing the best age verification system?
In this article, we will look at what age verification is (and its related terms), why it has become so relevant, how it runs inside a mature ID verification stack, and how independent testing can help you select the solution that will work best.
Get posts like this in your inbox with the bi-weekly Regula Blog Digest!
What is age verification (and other related terms)?
Age verification is the part of an IDV system that answers one narrow question: does this person meet a defined age threshold? “18+” is the common example, but the threshold can also be “under 16” or “21+,” depending on the policy you are enforcing.
The result has to be supported by evidence and by controls that tie that evidence to the person completing the check, in the same session where access is being requested. Otherwise, a user could borrow someone else’s proof or replay a prior success.
It’s worth noting that age verification can be easy to confuse with similar terms. Product teams, lawyers, and regulators may use the same words to mean different things; that’s why we’re also going to explore some related terms and see what they may imply.
Age estimation
Important: age estimation is not proof. It is an automated prediction of likely age or age range, usually based on a face image or a short selfie video. It is useful because it can be quick and low-friction, but it always has uncertainty.
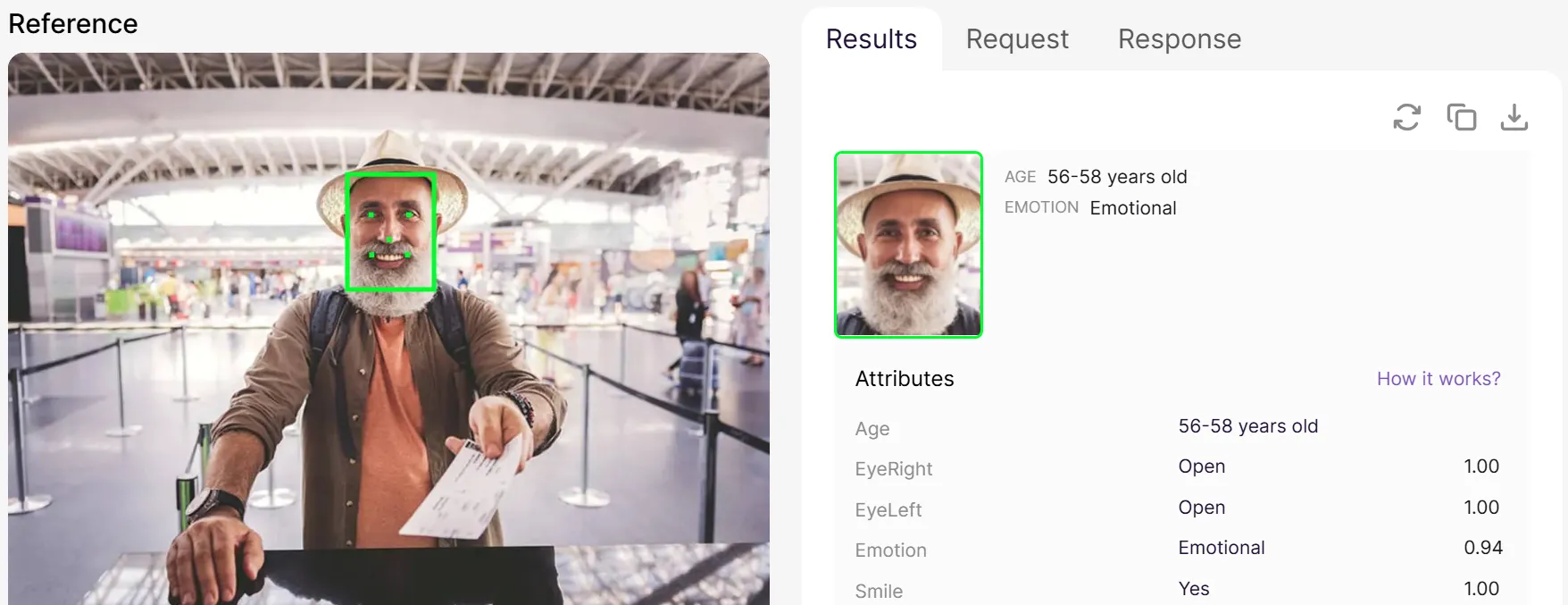
An age estimation output as seen in Regula Face SDK's web demo (available on our website).
Here’s a practical way to use it as an early signal:
If the estimate is clearly above the threshold, the system may allow access or accept a lightweight confirmation step.
If the estimate is near the threshold, the system routes the user to a higher-certainty method.
This is why “challenge age” exists. Instead of letting the threshold sit exactly at 18, the system sets a buffer (for example, 21 or 25) so borderline users do not slip through. The buffer is not arbitrary: it is typically based on measured error around the threshold in real capture conditions.
Age assurance
Age assurance is the umbrella term for the whole control system that prevents underage access in real use. It includes the methods, the routing logic, the monitoring, and the response plan when users try again after failing.
This is what is typically included into age assurance:
Step-up logic for borderline cases
Retry handling and suspicious repetition detection
Controls against account sharing after a successful check
Periodic re-check triggers when risk changes (for example, unusual behavior, new device, or a high-risk feature)
Age gating
Age gating is the lightest version of the concept: a checkbox, a birth year field, or a click-through confirmation. It can be acceptable for low-risk contexts, but it is not evidence-backed.

A typical example of age gating in an online liquor store.
Why age verification is getting more and more attention
Last year was massive for age verification, as regulators across the globe started imposing more and more strict rules for performing this operation. The UK’s Online Safety Act alone made headlines in dozens of major outlets, stirring up public debate about the balance of security and privacy.
With that, let’s explore the big developments of 2025, which are already paving the way for what’s to come in 2026.
Australia puts great emphasis on age assurance
As of December 10, 2025, “age-restricted social media platforms” must take reasonable steps to stop Australians under 16 from creating or keeping accounts. The legal risk sits with platforms, with court-ordered civil penalties that can reach AUD 49.5 million (150,000 penalty units) for corporations.
On top of that, Australia added a second pressure point: adult-content access through search and infrastructure providers. Age-Restricted Material Codes were registered on June 27, 2025, and are scheduled to take effect on December 27, 2025, applying to hosting services, internet carriage services, and search engine services. In practice, this means that major search engines would need to apply age assurance for signed-in users trying to access pornography and other restricted material, backed by penalties that can reach “almost $50 million per breach.”
It’s important to note that the law does not prescribe a single technical method, leaving platforms to show that their controls meet the “reasonable steps” standard. Some major companies have thus taken radical steps: for example, Snap says it will lock accounts identified as under 16 in Australia.
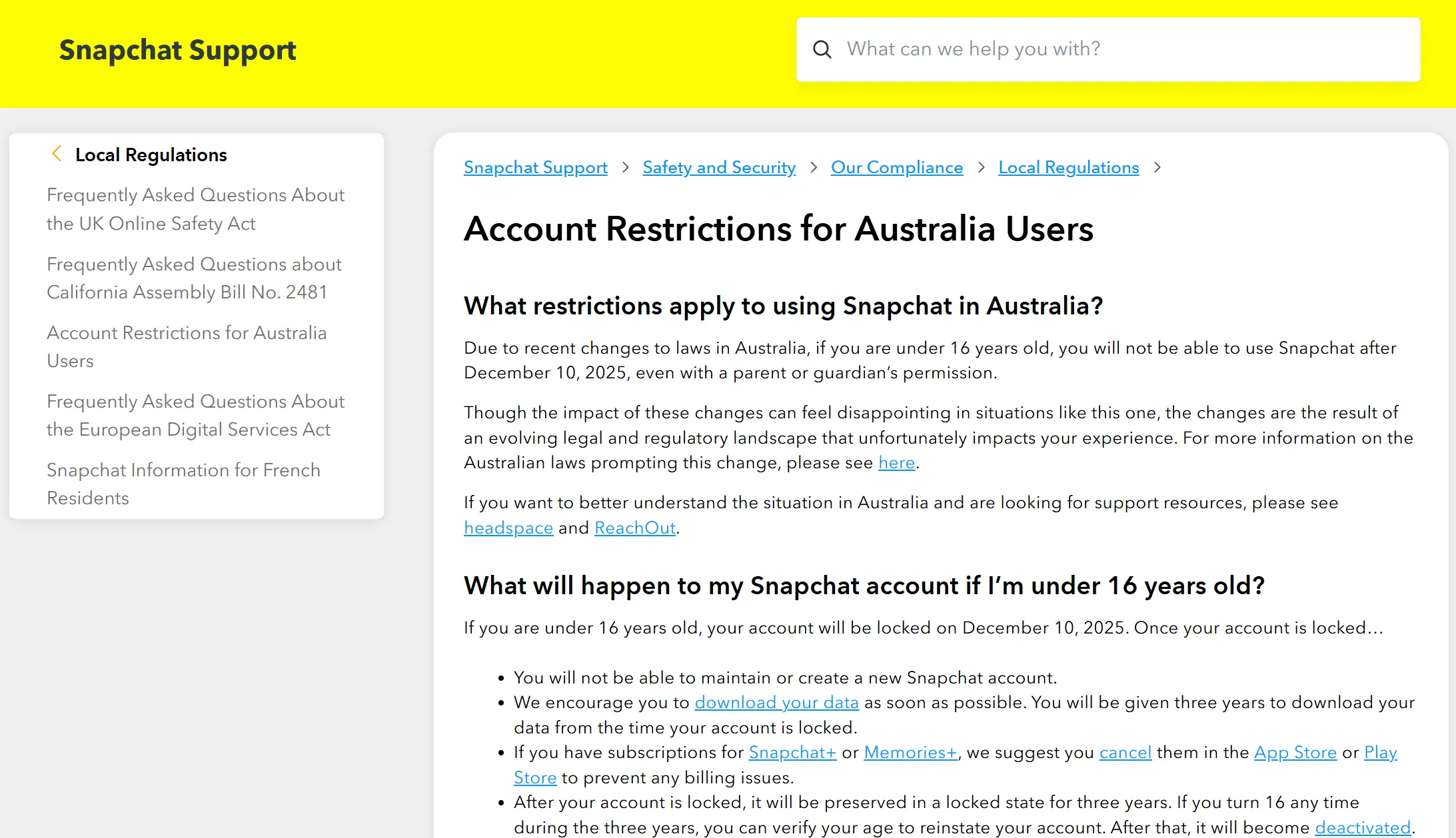
The Snapchat support page leaves no room for ambiguity.
It also describes multiple age-check options for users who need to confirm they are old enough, including a bank-based identity option, and third-party processing options that can include photo ID and facial age estimation. Snap also states that, for those third-party checks, it receives only the verification outcome rather than the underlying ID scan or bank details.
The UK defined a “highly effective” age verification process
The aforementioned UK’s 2025 guidance under the Online Safety Act is a big reason age verification ended up in mainstream headlines. It explicitly stated what kind of age assurance is deemed effective enough to fit their requirements, hence setting very specific expectations of IDV vendors.
A process counts as highly effective only if it satisfies all four criteria: technical accuracy, robustness, reliability, and fairness. More specifically:
Technical accuracy is about correct classification under controlled, test-style conditions. Ofcom’s guidance ties this to evaluation against suitable metrics and evidence that the method can correctly determine whether a user is a child in lab-like tests.
Robustness is where the guidance gets specific about binding and anti-bypass controls. For photo-based checks, it ties photo capture at the time of upload and liveness detection to reducing “borrowed adult” attempts, and it explicitly notes liveness as a defense against children using still images of adults to pass face-based estimation.
Reliability is about outputs being reproducible and grounded in strong evidence. Ofcom defines reliability in terms of reproducibility and “strength of evidence,” then mentions why that matters: without it, the same person could be classified differently across attempts.
For ML-based methods (including face estimation and photo-ID matching), it goes further and talks about variance and model drift over time, with an expectation of testing during development plus ongoing monitoring of KPIs once deployed, and retraining when performance problems appear.Fairness is defined as avoiding or minimizing bias and discriminatory outcomes. Ofcom discusses performance differences across groups (it uses facial age estimation as an example), and it expects testing and training on datasets that reflect the target population. It also introduces outcome/error parity as a way to examine performance across characteristics such as race and sex.
Europe sets a privacy-first reference design
Europe’s 2025 direction is interesting because it treats privacy as part of the technical bar for “effective” age assurance. The Commission’s guidance on protecting minors under the Digital Services Act does talk about accuracy and reliability, but it also mentions resistance to circumvention. Then it goes further and names non-traceability and data minimization as explicit targets.
In practice, that may change the product choice process: instead of asking “Can you check age reliably?”, teams may ask “Can you check age while respecting privacy guidelines?
The Commission’s recommended “double-blind” concept is a good example of the mindset. It implies a split of knowledge: the service should get only the outcome it needs to apply a rule, and the party that issues or validates the proof should not learn where the user is presenting it. When guidance names mechanisms like anonymized cryptographic tokens and zero-knowledge proofs, it is a signal that regulators expect builders to aim for privacy-preserving engineering.
What an age verification process looks like inside an IDV stack, step by step
Not all IDV stacks contain age verification, as some companies simply don’t require such checks. However, in view of the above changes in regulations, we are seeing more and more implementations of this security measure.
How exactly does it work inside an IDV stack? Let’s break the online age verification process down step by step:
.svg)
Step 1: Capture a live face sample
The client captures a short selfie video or an image burst. Before the system gets into age verification, it first it runs quality assessment to decide if the input is usable:
Face size and position in frame
Sharpness and motion blur
Pose and expression constraints
Occlusions (hair, glasses glare, masks, hands)
Lighting balance and overexposure
If the quality is too low, the user may be required to repeat the capture. Quality is important, because many errors near an age threshold can come from messy capture conditions rather than inadequate verification systems.
A practical tip: Quality guidance should be specific. “Move closer” and “more light” will help you reduce retries much more than the generic “try again.”
Step 2: Run liveness and capture-channel defenses
This step is there to eliminate still images and screen replays as potential threats. Software like Regula Face SDK can perform robust liveness checks (passive and/or active) to make sure that the user is a live person, not a fabricated imitation of one.
In parallel, the system protects the capture channel itself. The idea is simple: the app should not accept a replaced camera feed or a synthetic stream. A “live” sample should only be accepted inside that one session, within a short time window, and with server-side consistency checks.
Step 3: Detect, align, and normalize the face for inference
Now the system prepares the sample for age estimation. More specifically, it:
Detects the face and landmarks.
Aligns the face to a canonical pose.
Normalizes the crop and scale.
Standardizes color and exposure in the model’s expected format.
Produces an internal face representation used for inference.
There is also a privacy choice involved that affects both performance and perception. A tighter crop reduces background capture and makes it easier to justify data minimization. If the crop is too tight, you can lose cues and increase error.
The correct balance comes from testing on real user capture, especially around the threshold ages that are the most important.
Step 4: Estimate age
A mature pipeline does not treat the output as “the user is 19.” It treats it as “the user appears to be in X age range, with Y confidence, under Z conditions.”
There are two reasons for this:
The model output is inherently uncertain.
Your access decision is based on risk around the threshold, and not on a cosmetic age number.
Internally, what matters is the chance that a user under the threshold is incorrectly classified as above it.
Step 5: Apply challenge-age routing and step up borderline cases
This is where the age estimation stage turns into a verification flow.
Instead of using the legal threshold directly, the system sets a buffer above it (a challenge age). Users who are clearly older than the buffer can pass the first stage. Users who fall below the buffer do not automatically fail, but they do not pass either. They are routed into a higher-certainty method.
Common step-up options include:
Document-based age checks (extract birthdate and confirm authenticity).
Privacy-preserving age proofs (confirm “over threshold” without disclosing birthdate).
Additional binding steps if the risk of “borrowed adult” is high.
This is one of the places where you can keep the user experience reasonable without weakening the control. Most users do not land near the threshold, and the buffer keeps the high-friction path limited to the cases where it actually reduces risk.
Step 6: Convert the outcome into a claim
Once the age verification system reaches a decision, the stored record should be small:
Pass/fail for the threshold
Method label (estimation-only vs. estimation-plus-step-up vs. document vs. credential)
Issuance time and freshness window
An audit reference for internal traceability
How independent testing chooses the best age verification solutions
In 2026, a claim that a model is accurate can only be taken seriously if it’s backed by a reputable tester. In today’s ever more regulated world, businesses need third-party evidence that a regulator, auditor, or risk team can trust.
In the context of an online age verification process, one such reliable organization is NIST (National Institute of Standards and Technology). Its Face Analysis Technology Evaluation (FATE) Age Estimation and Verification (AEV) report provides detailed results for submitted age estimation and age verification algorithms, and it keeps the report updated as new submissions are added.
What makes the AEV reporting especially relevant to age assurance teams is that it really goes into detail when it comes to critical metrics:
MAE (Mean Absolute Error): Average age miss in years across the test set (NIST’s primary estimation accuracy measure).
MDAE (Median Absolute Error): The “typical” miss in years at the midpoint of cases, less sensitive to extreme outliers than MAE.
ACC(T) (Accuracy within tolerance): The share of samples whose estimate lands within ±T years of true age (often easier to interpret than MAE).
False positive rate in Challenge-T: The rate at which under-limit users are incorrectly estimated at or above the challenge threshold and would slip through unchallenged (underage leakage risk).
False negative rate in Challenge-T: The rate at which of-age users are estimated below the challenge threshold and get pushed into step-up (adult friction rate).
FTP (Failure-to-process): How often the algorithm declines or fails to return an estimate, which drives retries and step-up volume in production.
Gini coefficient (demographic variability): A compact measure of how uneven accuracy is across demographic groups, useful for spotting disparity risk.
Overall, NIST’s AEV results map directly to the two outcomes regulators and businesses care about the most: minors slipping through, and legitimate users getting pushed into extra friction.
As for Regula’s standings in the NIST report, Regula Face SDK topped the list of ID verification vendors as the most accurate age estimator across six geographic regions. Namely, Regula ranked among the top three in two of the most critical age assurance scenarios: Challenge 25 and Child Online Safety (ages 13–16).
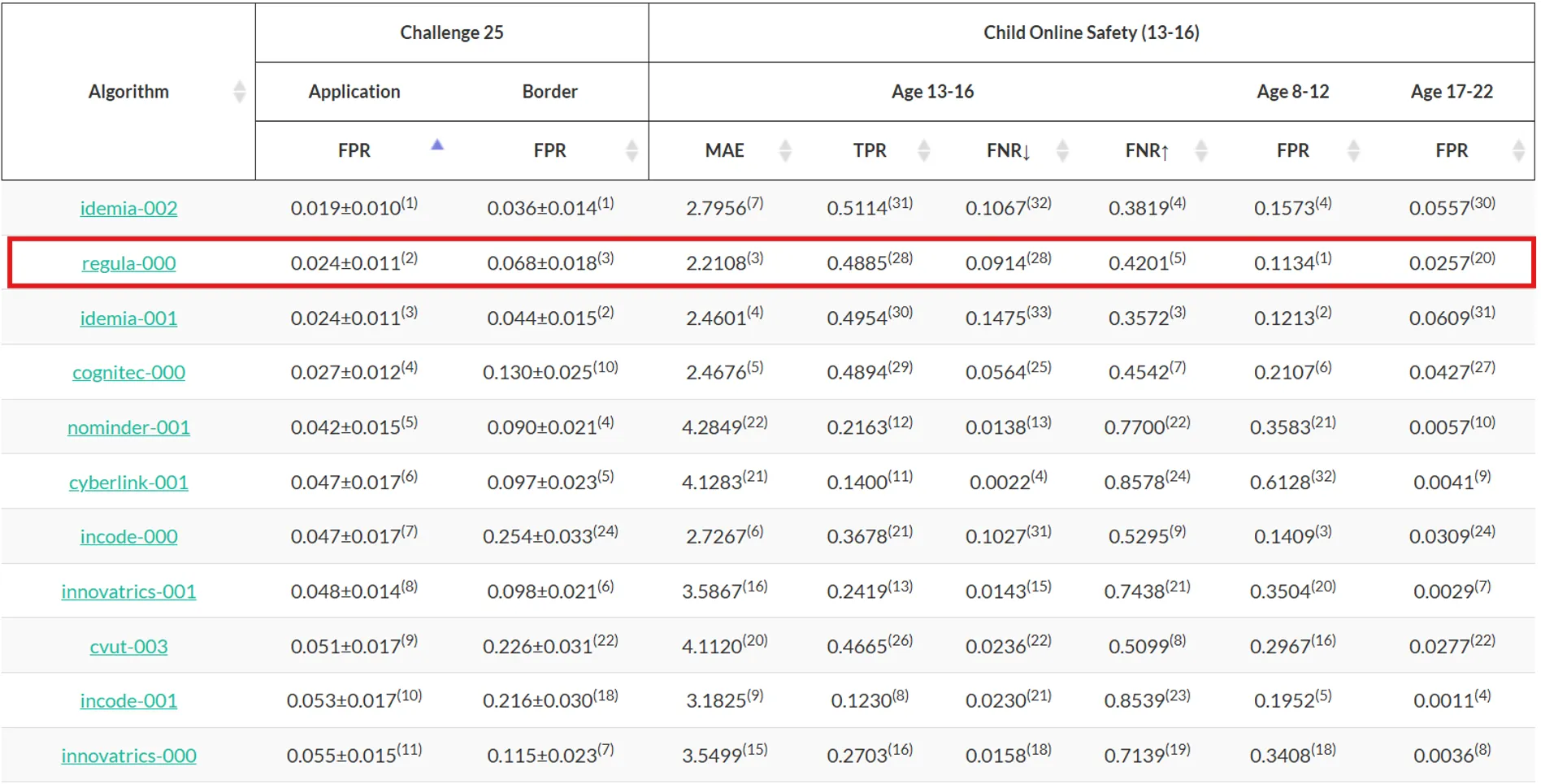
NIST's breakdown of IDV vendor performance for Challenge 25. Regula is highlighted as one of top performers, with low false positive rates.
How Regula provides industry-leading age verification
With seismic changes in regulations worldwide, we will surely see fewer and fewer simple checkboxes to verify users’ age. Businesses will no longer be able to afford ineffective age assurance, as pressure on them will mount.
That’s why we will be seeing more widespread use of advanced age verification solutions that are not only reliable, but also compliant with privacy laws. One such solution is Regula Face SDK, a cross-platform biometric verification solution that can support your age assurance with:
NIST-benchmarked age estimation performance: Reliable outcomes, confirmed by public, government-run testing that you can cite in your compliance documentation.
Challenge-age friendly outputs: Age estimation that supports buffer-based routing (challenge ages) so borderline cases can be stepped up to a higher-certainty check.
iBeta-tested liveness detection: Built-in liveness options (passive or active) to combat biometric identity fraud involving photos or screenshots, masks, video replays, deepfakes, and injection attacks. Regula Face SDK has passed iBeta Presentation Attack Detection (PAD) testing at Level 1 and Level 2, aligned with ISO/IEC 30107-3.
Quality gating: Face quality assessment (pose, blur, lighting, occlusions) that prevents low-quality capture from becoming a noisy “pass” near the legal threshold.
Cross-platform capture consistency: A unified capture and scoring pipeline across supported platforms so your age policy behaves consistently.
Near-absent bias: The SDK estimates the user’s age with high accuracy across all racial demographics, protecting minors and businesses alike.
Adaptability to various lighting conditions: The SDK operates effectively in almost any ambient light.
Have any questions? Don’t hesitate to contact us, and we will tell you more about what Regula Face SDK has to offer.



