

Key takeaways:
-
Training AI for liveness detection requires a large, relevant sample base and at least two separate datasets: one for training and one for validation.
-
A reliable dataset should reflect real users across ethnicity, gender, age, physical features, accessories, devices, lighting conditions, and capture environments.
-
The dataset should include both positive samples (legitimate user images) and negative samples (fraud attempts).
-
The main source of errors in AI-based liveness checks is an imperfect dataset: an insufficient number of samples, imbalances, mislearning issues, etc. To improve the performance, you’ll need to adjust (and sometimes retrain) the entire dataset.
Remote onboarding has one obvious weakness: you cannot physically see who is holding the camera.
Sometimes, there’s a real person on the other side. Sometimes, there is a printed photo, a replayed video, a mask, AI-generated media, or an injected video stream designed to impersonate one.
That is the job of liveness detection: to help confirm that the biometric sample comes from a real person physically present during verification.
However, as with many other things these days, liveness detection uses AI. That means reliable AI-based liveness detection starts long before a user takes a selfie — with the datasets, labels, validation rules, presentation attack samples, and retraining cycles used to teach the model.
This article looks at that behind-the-scenes work: what it takes to train AI for liveness detection, where the process can go wrong, and why data quality determines whether the system catches spoofing attempts without blocking legitimate users.
For a closer look at the spoofing methods liveness systems are designed to catch, see our guide to presentation attacks in biometric verification →
Why does liveness detection need AI?
All modern liveness checks use AI in one way or another for a simple reason: effectiveness.
AI algorithms process large amounts of data in real time, and make it possible to verify users’ liveness without noticeable delays.
Neural networks are continuously trained and updated with new data, so their performance becomes more effective over time.
Last but not least, AI can handle many liveness checks simultaneously. That makes it ideal for services with large user bases, such as online banking, remote onboarding, and e-commerce.
However, the power comes at a price.
You might also like: Can I Use ChatGPT for Identity Verification?
The model needs more examples than you think
Since neural networks learn to perform tasks by analyzing existing data, you’ll need a lot of relevant data as training material. This data can vary depending on the method: passive liveness will require images, while active liveness will require videos.
When we say “a lot of data,” we do mean it. To have your network ready for fieldwork, you’ll need not one but two datasets:
-
A dataset for actual training. These samples must be images of the same nature, quality, and variety, as they will then be submitted by real users.
-
A dataset for training result validation. These samples are needed to test how well the network performs. It’s important never to feed items from this dataset to the network during training to avoid “teaching to the test.” In this case, the network might perform well in your testing sandbox, but fail to generalize to new data in real-world applications.
For example, if your validation dataset contains 1,000 samples, a single error translates into a 0.1% error rate. To reach a 99.999% accuracy rate, you’ll need 100,000 examples to prove that the network performs reliably under diverse conditions.
But that’s not all.
Get posts like this in your inbox with the bi-weekly Regula Blog Digest!
You can’t teach fraud detection with only honest selfies
The goal of a liveness check is to mitigate identity fraud. That’s why you’ll also need samples of fraudulent images — as if someone tries to cheat the system. As we said above, accuracy comes at the cost of the amount of data. So, to be 99.9% sure of detecting an attack, half of the items in your dataset should be representations of attacks.

Regula team members performing as fraudsters to train the AI
Real users don’t all look, move, or dress the same
It’s also important to balance your dataset to avoid biases in AI behavior. If your dataset is built mostly from samples collected in one region, say in Western Europe, it may underrepresent users from other regions, ethnic backgrounds, or skin tone ranges. As a result, an otherwise effective system can perform poorly when verifying people outside the dominant training sample.
Also, people often wear accessories, like glasses, hats, scarves, and more. These items hide parts of the face, making the task more difficult, since it’s not always possible to ask a person to remove an accessory. Accessories can also be used in fraud attacks to disguise imperfections in masks. That’s why it is important to have these kinds of samples as well, so the network can learn how to handle such attributes.
When training Regula’s liveness check module, we consider the following attributes:
-
Demographic variation, including ethnicity, gender, and age
-
Physical features: variations in facial hair, makeup, scars, etc.
-
Accessories: eyewear, headgear, and other accessories that people commonly wear
The actual proportion of attributes depends on your context. Ideally, your dataset should correlate with the geographic area in which your business operates. So, if your target market includes countries where head coverings are commonly worn for religious reasons, you’ll need a larger share of such samples.

Sometimes AI learns the wrong lesson
One of the most significant risks is that the AI system may learn incorrect patterns that result in false positives or negatives.
Such errors stem from the way neural networks are trained. When you feed the network with samples, it selects the features that let it give correct answers. Then, the network remembers and generalizes these features so that it can apply them to evaluate a new unfamiliar sample.
The problem is that a training dataset may contain misleading patterns. However, a training dataset might contain systematic errors. For example, you might have collected a large set of “attacks” using a camera with broken pixels. These defects might not be visible to the naked eye, but the model may still remember them as a meaningful fraud signal.
Samples submitted by real-world users won’t have this peculiarity, so the network will probably identify fraudsters as genuine users.
The same risk appears when the dataset is too narrow. If you train a model using only 10 masks, it’ll likely learn to identify those specific masks with high accuracy. However, when a real fraudster uses a different mask, the model might fail because it hasn’t generalized the features sufficiently.
Fixing these errors involves adjusting the entire dataset — either by removing misleading data, adding new examples, or both — to help the network learn the correct patterns.
💡By the way, it’s dangerous to use AI image generators to create more samples for your training datasets. Synthetic images often come with distortions, and your model can start treating them as an important feature.
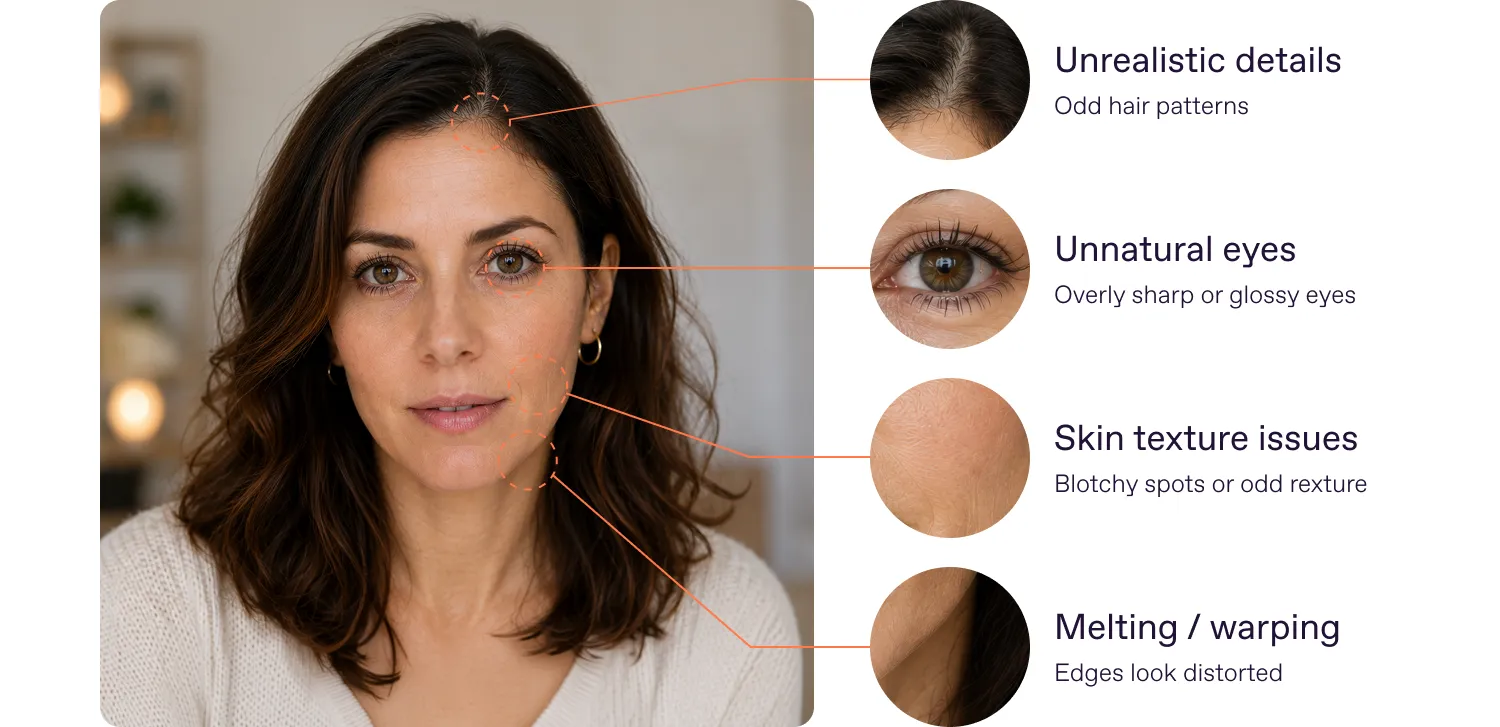
One bad result rarely has one neat cause
The network takes lots of parameters into account. Technically, you often won’t even know exactly what it picked up on as an important parameter: a texture in the eyelid area, or a color match in a few spots on the forehead and cheeks.
It is almost impossible to pinpoint the root cause of an error in one specific example. So, all errors are addressed through broad statistical analysis, while isolated cases (3-5 examples of errors) are of little help and cannot guide systemic improvements.
Human judgment still shapes the model
To train a model, you need marked-up data. In the case of a liveness check, a team member literally labels each image as “live,” “not live,” or “unknown.” Unfortunately, humans are prone to making mistakes.
Errors at this stage are especially painful as they severely impact the overall result, while being hard to find. In some cases, the team may need to review all the dataset again.
To minimize the risks, we at Regula use detailed guidelines and train the employees responsible for sample markup so that labeling decisions are consistent and not dependent on one person’s interpretation.
In addition, we perform cross-validation of marked-up data. Two people independently label the same samples. In the case of mismatched results, the sample goes to a third, more experienced reviewer. If the third person cannot make a clear decision, we consult with domain experts and developers. If a decision still can’t be made, we put such examples in a separate group.

This sample may be difficult to mark up because it is unclear whether the image shows a real selfie or a screen demonstration.
You cannot fix AI like a line of code
AI networks mimic human trial-and-error learning processes, so they work more like humans than traditional deterministic algorithms. This fact means two things:
-
They are not infallible.
-
Fixing a mistake in AI behavior isn’t as straightforward as updating a line of code.
A traditional deterministic system follows predefined logic: if X happens, do Y. A neural network works differently. Its behavior depends on patterns learned across many samples, so improving one scenario can unintentionally affect performance in another. That’s why you need to systematically work with the entire dataset: re-balance it, add more samples, and run error correction.
Again, the size and quality of the dataset matter. If it includes only a handful of samples, the neural network won’t perform as expected in real-world applications.
How to prepare a good dataset for a liveness check?
A good liveness dataset is never “done.” It needs to grow, be checked, and be corrected as users, devices, capture conditions, and fraud tactics change.
In practice, this comes down to three steps:
| Step | Why it’s important |
|---|---|
| 1. Extend and update your dataset | Continuously adding new samples to your datasets helps the model adapt to a wide variety of relevant scenarios, and improves its reliability. A narrow dataset creates narrow judgment. |
| 2. Revise the dataset | Every dataset needs to be reviewed for mislabeled images or underrepresented groups, and contain the data which is as accurate and inclusive as possible. Such data imbalances can become a large model problem later. |
| 3. Automate what can be checked safely | Automation can speed up parts of dataset review, such as duplicate detection or distribution analysis across demographic groups. |
When training our networks at Regula, we apply principles of auto-learning. The process goes in iterations. A trained network marks up the data, which is then reviewed by a human. The human either confirms the results or corrects them. These corrections are valuable as they highlight the network's imperfections. Once a sufficient number of corrections is accumulated, a new cycle of training and automatic markup begins, continuing the process in a loop.
The idea is simple, yet execution is not.



