

In the past, most image processing was done by standard algorithms. Neural networks are like image processing tasks that standard algorithms used to perform, but on steroids. The speed increased tremendously and made things that were previously deemed impossible… well, possible.
Despite the ever-growing impact, many still don’t know what neural networks are and how they work. In this post, we’ll guide you through the basics, and see how they are used in the identity verification field.
Let’s get started.
Subscribe to receive a bi-weekly blog digest from Regula
What is a neural network?
A neural network is a computer algorithm inspired by the structure of the human brain. It analyzes large amounts of data to find patterns, learn from them, and then apply what it has learned to predict the output for similar queries.
In practice, these queries can be almost anything: from answering questions and identifying objects to real-time translation, or even creating digital art.
A neural network consists of layers of interconnected nodes (“neurons”) that process information in parallel. The first layer is called the input layer, and the last one is called the output layer. The layers in between are called hidden, although they perform most of the computation.
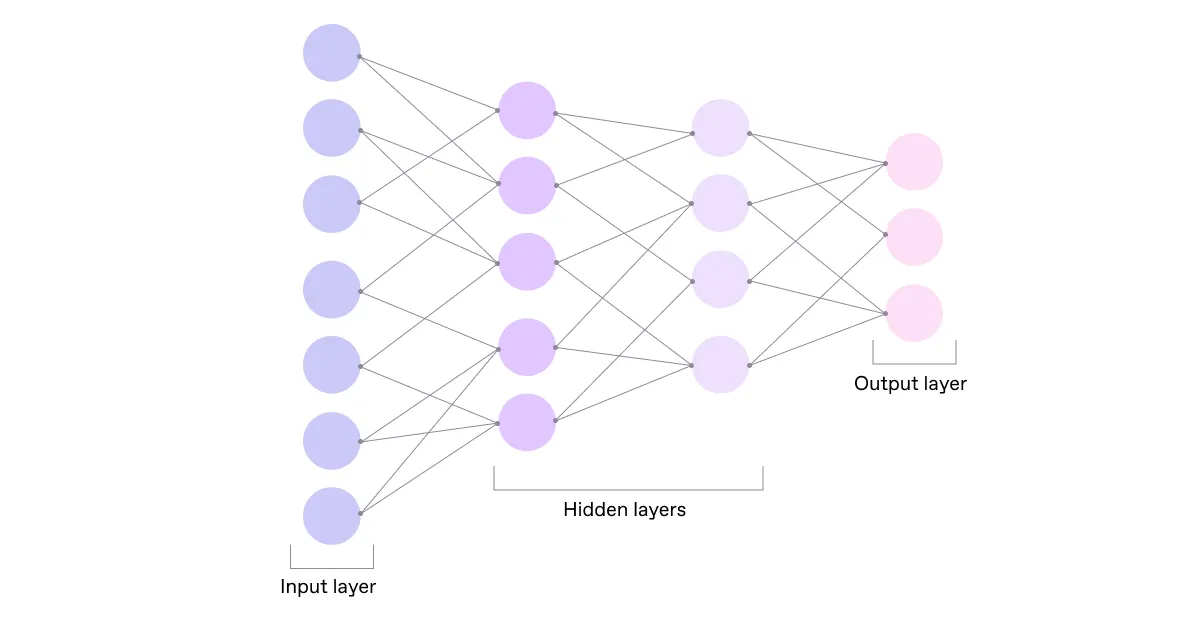
The nodes of one layer are connected to the nodes of the next layer through connections. That means there can be several other nodes they receive data from and several nodes they transmit this data to.
Each of the connections is assigned a value, or “weight.” When the network is fed a piece of data, the nodes receive a different value over each of their connections and multiply it by the associated weight. Then they sum up the results and pass the value through the activation function.
Activation is a mathematical evaluation to decide if the node’s input to the network is important or not. If the resulting value exceeds the threshold value, this particular node “gets activated,” meaning it’ll transmit the data to the next layer.
The final layer is essentially our result.
Depending on the model, we might need to perform additional operations—a special activation function—with the output layer to get the result in a more digestible format. For example, in a classification model (we’ll talk about neural networks’ applications below), the node with the highest value in the output layer determines how the input object is classified.

The types of neural networks
There are two types of neural networks depending on the direction they can transmit the signals.
If the data flows in one direction, such networks are called “feed-forward.” In its basic form, it’s the simplest variant of neural networks, but its iterations can be very advanced.
For example, one of the most popular models used today is convolution neural networks (CNNs), which also have feed-forward architecture. CNNs are essential for various computer vision tasks like image recognition and classification, including face recognition.
If the data travels in both directions, it’s a “feed-back” neural network. An example of this architecture is recurrent neural networks (RNNs), where the data can form a loop: from input through layers to output, and then the output is used as input again. Such networks can be used, for example, for natural language processing.
How neural networks are trained
As we said earlier, neural networks learn to perform tasks by analyzing training data samples. These samples are usually hand-labeled. So, for example, an object recognition network can be fed thousands of labeled images of cats and dogs to find specific features for each animal and consistently match them to corresponding labels.
Initially, the weights and activation threshold are set to random values. Once the training dataset is fed and the output is delivered, it’s compared against the actual input to check whether the prediction was true or false. Based on this information, the weights are adjusted. After numerous iterations, the network gains enough “experience” to deliver acceptable quality and precision.
In the beginning, neural networks were able to solve the easiest binary tasks only. Something like distinguishing between red and green circles, while distinguishing between squares and asterisks was already out of their reach. Because of this lack of efficiency, neural networks were considered a dead-end for a long time.
Everything changed with the beginning of the era of big data. People realized that neural networks needed vast amounts of data to work properly. And everything was in place for that: the amount of processable data in the world increased tremendously and the hardware to deal with it was within reach too.
There’s a popular statement floating around the web that it takes about 10,000 data items to train a neural network. However, this number depends greatly on the variability of data. Training a neural network to distinguish red and green circles requires fewer samples than training to distinguish squares and asterisks. The latter is a more difficult task because asterisks resemble squares under certain angles. So, the more variation in input, the more data is required for training.
That’s in an ideal world.
Quite often, there is a deficit of input data. But even in such a situation, it’s still possible to train a neural network with the help of augmentation techniques. These techniques allow you to generate many similar items based on a single sample. Trained on these items, your network can go into the public, start collecting real data, and then improve the quality of output right in the process.
At the same time, you don’t always need to start from scratch. The neural network training process often involves reverse engineering, where you take a big neural network and start cutting it into a smaller one. The purpose is to reduce the size of the network while preserving the quality of output. When the quality of performance starts to downgrade during the cut, you stop the procedure. This is called “optimal brain damage.”
Optimal brain damage is the concept that underlies the methods for neural network compression. Compression is crucial to fit a network into a device that has storage constraints, such as a smartphone. Plus, the smaller the network, the faster it works and the less it drains a battery.
Now that we've finally gotten through the basics, let’s have a look at how neural networks are applied for identity verification.
How neural networks are used for identity verification
It’s a hard task to give a set list of types of neural networks, as new types continue to emerge with the development of AI and machine learning. In the identity verification field, we use four major models:
Detection,
Segmentation,
Classification,
and Regression.
1. Detection
A classic detection model takes an image as input and outputs rectangular areas and the probability (confidence) with which the object can be found in this area. It can also identify if there are multiple objects within the frame.
The object can be anything: an ID, someone’s face, or elements within a document, such as a signature, a hologram, or just a text field. If it’s the latter, the detected text strings can then be passed to the optical character recognition (OCR).
Optionally, you can also train the network to deliver some additional information, such as the rotation angle of the detected object, face landmarks, etc.

Detected! The document is somewhere in the red rectangle.
2. Segmentation
What a segmentation model does is basically a classification of pixels in an input image. It labels each pixel with a specific class, allowing you to get more detailed information about the image.
Being a logical extension of the detection model we described above, segmentation can help you learn the exact shape of a detected object, fine-tune its edges, and sort out which pixel belongs to which element. For an ID card as an object in our example, the classes will be:
the document,
bordering,
- corners,
and the background.

Here is how a segmentation neural network “sees” the exact position of the document.
Once the detection and segmentation models have completed their tasks, simple transformation algorithms come into play for more convenience. These algorithms can deskew objects shot at an angle before passing them on for further processing. That often comes in handy for remote identity verification, where you need to rely on users’ skills at taking photos of their documents.

The neural network converted an image of a document to a standard view which is convenient to work with.
3. Classification
In the segmentation model above, the network assigns a class to each pixel of an input image. However, suppose you want to know which object is there in general. In that case, you need to assign a class to the object as a whole. This model is known as classification.
Classification tells us the degree to which an input object belongs to each of the classes. For example, a document type classification network outputs the top classes—document types—to which this object belongs with the highest probability. In our case, it’s a Latvian ID card, not a Utah driver’s license.
Classification models must always have a certain number of classes pre-defined by an engineer in advance. For example, classes for a network that distinguishes cats from dogs by a photo will be “cat,” “dog,” and “not defined.”
Having this “not defined” class is essential to avoid ambiguities. All the potential outputs we expect to get must be divided into non-overlapping sets that fully cover the use cases, including the ones where proper classification is impossible. Otherwise, the network will have to choose from obviously wrong answers.

The neural network classified this document as a Latvian ID card, issued in 2012.
4. Regression
In a regression model, the goal is to predict the output value. Unlike classification, where they process the input data to assign a class from a given limited list (Is there a face in the image? Who’s it? Is it a male or female?), regression assigns new values, for example, estimates the age of a person in a photo.

Quite an accurate prediction since the person was 36 at the moment when this document expired.
It’s important to note that today, neural networks are often used in combination. We at Regula have a Swiss army knife of networks: some networks are used for preliminary data quality assessments, others check out the background and lighting to tell if they meet the requirements, and then there’s a network that verifies the eyes are open and looking at the camera (if it’s a biometric check), and another one runs a liveness check—just to name a few.
This combination of neural networks usually works in the background of a single app to deliver a final result: passed or failed identity verification.
You might also like: Can I Use ChatGPT for Identity Verification?
Putting it into practice: A real-life use case
Now let's move from theory to practice and see how neural networks can be used specific for identity verification purposes. For convenience, we’ll use Regula’s solutions as an example.
Suppose a passenger comes to an airport where Automated Border Control (ABC) is available. Just like with a traditional process that involves a border officer, ABC needs to make sure that the ID document is valid and its presenter is actually the person whose photo is printed in the document.
The passenger puts their document on a reader and looks at a camera. This is where a set of neural networks trained for identity verification purposes steps in.
Once the document reader has scanned their ID, several neural networks purpose-built for document verification spring into action. They:
detect the document and identify its type;
assess the presence of security features, such as MRZ, barcode, and RFID chip;
read the data;
cross-check the data from different elements;
conduct an authenticity check.
While the document reader is working, the passenger undergoes a biometric check.
ABCs have a built-in module for face biometric checks. Neural networks can, for example, ensure that the passenger’s face is clearly visible, the person is looking directly into the camera, and there are no face occlusions like a mask or sunglasses.
They can also evaluate facial expressions, since it’s important for facial biometric examination to check that the face is neutral, not smiling, and not with the eyes unnaturally wide open.
An additional neural network is integrated into the face match procedure: it compares the photograph taken at the border control against the portraits in the ID, chip, and visa. If they match, the identity is verified, and the passenger can proceed.
Neural networks are key for identity verification
There were times when people couldn’t imagine a car and dreamt about faster horses. The same goes for identity verification. Instead of relying on humans’ experience and intuition (“faster horses”), neural networks effectively cover identity document processing, verification, and authentication processes.
The best part: all those operations happen in seconds, and their results are even more accurate than manual handling.
The speed and flexibility neural networks provide are a big advantage for those who harness this power. No wonder almost every product in Regula’s portfolio leverages neural networks to deliver reliable results in a snap.
Now, we’d like to hear from you.
What about neural networks thrills you most? Did you know that neural networks are widely used for identity verification? Will they replace humans over time? Don’t hesitate to share what you think with us in Regula’s LinkedIn group.



