

In brief: Arabic, Chinese, Japanese, and other non-Latin IDs create trouble when OCR output looks plausible, but names, dates, and fields stop matching throughout the document. The most reliable way to cut that review work is to use software that reads the script correctly, understands the document layout, and checks every available data source against the others.
By mid-2024, the world had 304 million international migrants, and UN Tourism says 2025 closed with an estimated 1.52 billion international tourist arrivals. For KYC teams, that means dealing with more ID documents printed in Arabic, Chinese, Japanese, Hindi, Bengali, Sinhala, Lao, Khmer, Greek, Georgian, and other scripts outside the Latin alphabet.
In this guide, we will look at the scripts that create the biggest headaches for verification teams, especially Arabic, Chinese, and Japanese, and we will also cover the OCR capabilities that help reduce script-related errors.
Get posts like this in your inbox with the bi-weekly Regula Blog Digest!
The non-Latin scripts that create the biggest issues for KYC teams
In practice, the scripts that deserve the closest attention are the ones that combine three traits:
-
a large speaker base,
-
frequent use in verification flows,
-
a high chance of causing OCR, parsing, or matching errors.
For this article, we will focus on Arabic, Chinese, and Japanese, while also noting several others in the honorable mentions section.
Arabic
Arabic runs right to left, stays cursive in print, and most letters take different forms depending on where they appear in the word. Those traits make Arabic ID processing harder for many OCR engines.
Potential failure points include:
-
The first OCR step carries a lot of weight. Once the native Arabic field is read incorrectly, the Latin output derived from it will also be wrong, and that wrong value can then fail against the MRZ, chip, or customer profile.
-
Bidirectional layout creates extra room for field-order mistakes. Many Arabic-speaking countries print personal data in Arabic alongside English or French on the same document. An OCR engine that is not tuned for bidirectional content may process text in the wrong order or mix up nearby fields.
-
Weak image quality can change one valid name into another. If the ID scan is low-resolution, subtle script details can be lost or confused, turning تامر into ثامر (Tamer into Thamer).

A typical example of bi-directional content, as found in Bahrain’s national ID card.
For ICAO travel documents, the MRZ side of Arabic is more standardized than the OCR step itself. ICAO has a dedicated Arabic appendix with a recommended MRZ transliteration scheme meant to reduce ambiguity. As long as the Arabic source field is read correctly, the MRZ side becomes much more rule-bound. That will not always be true for the scripts below.
Chinese
Chinese ID verification creates a different kind of problem. Text usually runs without spaces, the character set is very large, and simplified and traditional forms do not always map neatly to each other. On top of that, OCR systems tend to handle some characters better than others, so a rare name character in a blurry or reflective image may be replaced with a more common lookalike.
Unlike Arabic, Chinese passports do not rely on a dedicated ICAO appendix for transliteration. Instead, the Latin passport name is shaped mainly by China’s own pinyin rules for personal names, plus the general ICAO rules for MRZ formatting. That means matching logic has to account for national spelling rules and document-history effects, not only OCR accuracy.

An example of no-space Chinese script on a driver's license.
Potential failure examples include:
-
Simplified and traditional forms of the same name can break a match. Good examples are 张伟 / 張偉 (Zhang Wei), 刘洋 / 劉洋 (Liu Yang), and 陈静 / 陳靜 (Chen Jing). These are the same names written in simplified and traditional Chinese, so an exact string check can reject a genuine match.
-
Passport spelling can differ for valid rule-based reasons. For example, the surname 吕 is written Lü in standard pinyin, but China’s National Immigration Administration says names with LÜ are printed as LYU in exit-entry documents. The same notice also says holders of older documents may ask to keep an earlier spelling for consistency. So one genuine record may show LYU, while another may still show an older form, even though the original Chinese name was read correctly.
-
Less common Han characters are harder to read under weak image quality. The Han script contains tens of thousands of ideographs, so OCR is more likely to confuse rare name characters with more familiar lookalikes when the image is weak.
Japanese
Japanese mixes several writing systems in ordinary text, usually without spaces: kanji, hiragana, katakana, and often Latin letters as well. OCR has to cope with mixed scripts and small sound marks in kana, while matching logic has to cope with the fact that the written kanji name and its official reading are not always the same piece of data.
In Japanese passports, the Roman-letter name depends on the registered furigana and the corresponding Roman spelling used in the passport application, so correct kanji OCR on its own does not fully settle the Latin form. Japan’s Foreign Ministry says passport applications should use the furigana recorded in the family register and the matching Roman-letter form.

Japanese domestic IDs may also show dates from different imperial eras on the same card. For example, a holder’s birth year may appear as 昭和40 (1965), while the issue year and expiration year appear as 平成22 (2010) and 平成25 (2013).
Japanese passports are more rule-bound than many people expect, but the rule set is national rather than a special ICAO appendix of the Arabic type. MOFA publishes a Hepburn romanization table for passport names, including rules for long vowels, double consonants, and spellings that do not follow the default Hepburn pattern. It also says non-Hepburn spellings may be allowed in some cases, and that once a passport spelling has been set, changing it is generally not allowed.
Potential failure examples during Japanese ID processing include:
-
Small kana marks can turn one valid name into another. In kana, a faint or missing dakuten can change the reading of a whole syllable. An OCR-type example would be カンダ becoming カンタ if the mark on ダ is lost or misread. This is an illustrative script-level example, not a quoted passport case.
-
Long vowels can produce valid Latin spelling differences. Under MOFA’s passport romanization rules, long vowels are often shortened in the default spelling. For example, 伊藤(イトウ) is normally written ITO, while a non-default form such as ITOH may be accepted in approved cases. Another example is 大野(オオノ), where the default form is ONO and OHNO may be accepted as a special spelling.
-
Current and past passport spellings can affect later matching. MOFA says that when furigana is not yet recorded in the family register, applicants should use the reading that matches the Roman-letter spelling in their current or past passport, and that this spelling cannot normally be changed while that situation continues. That means a later check may see a Latin spelling shaped partly by passport history, not only by the kanji name on its own.
Honorable mentions
Several other script families still deserve a place on a KYC officer’s watch list:
-
South Asian scripts: Devanagari, Bengali, and Sinhala often fail at the syllable-cluster level rather than the single-letter level, because vowel signs and other elements attach around a consonant cluster. A simple Hindi example is किरण / करण: lose the short i sign, and Kiran turns into Karan.
-
Korean: South Korea has an official Romanization system, yet the document spelling, the customer’s preferred spelling, and the version already stored in another system may still differ enough to trigger a match problem. A practical example is 박민수, which may appear as Bak Minsu under the official system and as Park Min Soo in another database.
-
Lao and Khmer: Lao spaces separate phrases rather than words, and Khmer also relies heavily on syllable structure, so line breaking and text splitting are easier to get wrong than in Latin-script text.
-
Cyrillic, Greek, and Georgian: On passports, the MRZ provides a fixed machine-readable Latin layer. On domestic cards, however, that extra anchor is often missing, so matching is less stable.
Why passports are easier than domestic IDs in non-Latin scripts
The same script can be easier to handle in a passport and harder in a domestic ID. Passports follow a common rule set, which makes the result more predictable. Domestic IDs often do not.
The core difference between passport OCR and domestic ID OCR for non-Latin scripts can be summed up as follows:
|
|
Travel Documents |
Domestic IDs |
Impact |
|---|---|---|---|
|
Latin-readable visible data |
Mandatory non-Latin VIZ data must also appear in Latin form. |
Rules are national; some cards have little or no Latin text. |
Domestic IDs rely more on native-script OCR. |
|
Machine-readable layer |
MRZ is standardized; eMRTDs may also add ICAO chip data. |
Often no MRZ; any chip or barcode is usually national in format. |
Travel docs usually allow stronger cross-checking. |
|
Electronic data |
eMRTDs follow ICAO’s LDS model. |
No single domestic equivalent; content and access rules vary. |
Chip data on domestic IDs is useful, but not a universal anchor. |
|
Layout |
Passport layouts are relatively constrained. |
Layouts vary much more by country and document type. |
Template coverage and capture quality matter more on domestic IDs. |
How KYC teams can cut false mismatches on non-Latin IDs
A lot of expensive manual review work can follow if the OCR system treats extraction, parsing, transliteration, validation, and comparison as one blurry process instead of a chain of separate checks. The controls below help reduce that review load at the points where the chain usually breaks.
Identify the document before you parse the fields
If the system does not identify the document type and field map first, it may read the right characters and still attach them to the wrong field. A Japanese driver’s license or a bilingual domestic ID cannot be treated as a simple Latin ID-1 card.
This is also where template coverage starts to affect review rates. For example, Regula IDV Platform can work with over 16,000 document templates from 254 countries and territories, and its OCR language coverage includes Arabic, Bengali, Sinhala, and many other non-Latin scripts.
Read the native script first, transliterate second
Arabic shows this most clearly, but the same order helps on any script with unstable Latin spellings.
Read the native field first. Then map it into the Latin form used for comparison. Only after that should you compare it with the VIZ, MRZ, chip, barcode, or customer input.
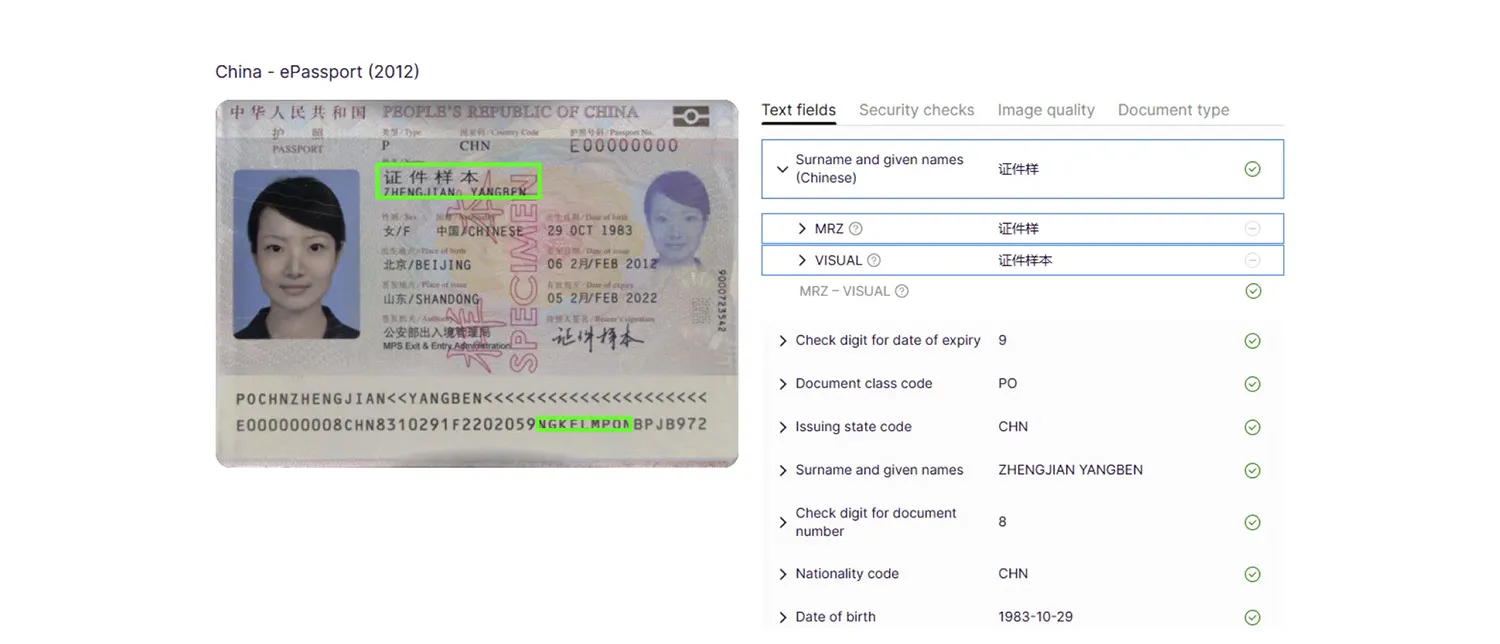
For example, during MRZ reading in Chinese passports, IDV software must convert the Latin script into the original Chinese name and match it against the visual data.
The software should also return separate visual, MRZ, barcode, RFID, and combined text outputs. That lets a KYC team see whether the failure started in native-script OCR or in the later comparison rule.
Compare every readable zone before you score the file
Non-Latin checks can fail when the system trusts the first readable line and stops there. Japanese passports with bracketed VIZ-only names are one example, but the same rule applies elsewhere: Arabic names may have a more familiar Latin spelling in the VIZ and a table-based form in the MRZ, while long names may be shortened in the MRZ yet remain complete in the visual zone or chip.
Strong document-reading software compares data from the visual zone, MRZ, barcode, RFID, mobile driver’s license, and digital travel credential sources.
Reject weak captures before OCR starts to drift
Weak captures hurt every script, but non-Latin IDs are less forgiving because small missing details can change a whole character, a whole syllable, or a whole field boundary. The easiest fix is often to reject bad input as early as possible.

The Chinese driver’s license, for example, is highly glossy with vibrant holograms, and even slight tilting causes bright reflections that OCR may interpret as light patches or random shapes across text.
For instance, Regula IDV Platform checks glare, perspective distortion, bounds, portrait presence, brightness, color, focus, and resolution during capture to decide whether the image is good enough to process. It also checks document liveness and geometry, so a laminated domestic card with glare does not have to move straight into shaky OCR and manual review.
Keep the document library fresh
Non-Latin document handling does not stand still. IDs are updated all the time, and software has to keep up with new layouts, numbering rules, and chip behavior.
If the document library falls behind, OCR can age badly, especially on domestic IDs, which often change more often than passports.
Maximizing OCR reading accuracy of non-Latin ID documents
No solution will read every non-Latin document flawlessly under every condition. The best results come from pairing a strong OCR engine with a large document-template library that helps the system interpret fields correctly.
Regula brings those pieces together. Regula IDV Platform supports over 130 OCR languages and more than 600 data field types, with a document-template library covering over 16,000 document templates from 254 countries and territories.
Its lexical analysis supports transliteration from non-Latin scripts into Latin and helps cross-check data fields. The platform also uses trainable neural networks for document-reading tasks.
With Regula IDV Platform, you will be able to:
-
Read and validate thousands of ID documents from around the world, including regions that use non-Latin scripts.
-
Read machine-readable zones (MRZs) and barcodes.
-
Read and verify RFID chips.
-
Validate digital signatures in ICAO-compliant barcodes and RFID chip data.
-
Verify dynamic security features, including holograms and optically variable ink (OVI).
-
And more.



