

TL;DR: OCR speeds up identity verification by extracting document data automatically. The technology is most valuable and precise when it works together with document templates, field validation, and cross-checks.
Identity verification often starts with a simple task: capture the data from an identity document and turn it into something a computer system can process. That sounds straightforward, but identity documents vary by country, layout, language, script, and security design, and even small inconsistencies may matter during a check.
In identity verification, the real question is not whether OCR can read text, but how well it works on identity documents in real conditions.
What is OCR?
OCR, or optical character recognition, converts text in document images into machine-readable data. In identity verification, it is used to extract personal data from passports, driver’s licenses, national ID cards, and other government-issued IDs so that the document can be processed automatically.
For example, Regula Document Reader SDK uses OCR to read data from nearly all types of identity documents issued across 254 countries and territories.
How does OCR work?
OCR starts with a digital image of the document. Once the image is captured, the system identifies text areas, recognizes characters and words, and prepares the extracted data for further use. Modern OCR usually relies on detection and recognition models rather than older character-by-character matching methods.
Generally, OCR processes a document in three stages:
Text detection. The technology launches a text detector, which is a special algorithm that pinpoints text areas within the document.
Text recognition. A recognition model proceeds to analyze the identified text. OCR technology uses pattern recognition and/or advanced machine learning algorithms to match characters in the text to letters and numbers in the chosen fonts and languages. The modern form of the technology can self-train in the process, improving the quality of text recognition with every processed document.
Post-processing. Finally, the system prepares the extracted data for use in downstream workflows. This stage may include comparing the results with a dictionary or database to correct errors, checking the logical structure of data, or normalizing the output so it can be used consistently in later checks.
Advanced modern OCR systems extract data from virtually any place within a document. They recognize and interpret not just the character sets but also the context of the data based on its position within the document or its relation to other data elements.
However, all this is feasible only if the image quality is good enough for the technology to process it.
How does OCR work with ID documents specifically?
In identity verification, OCR is not limited to data recognition and extraction. For example, the technology should not only read the passport holder’s name, but also check whether the data is printed in the correct font, format, and position for that specific document type.
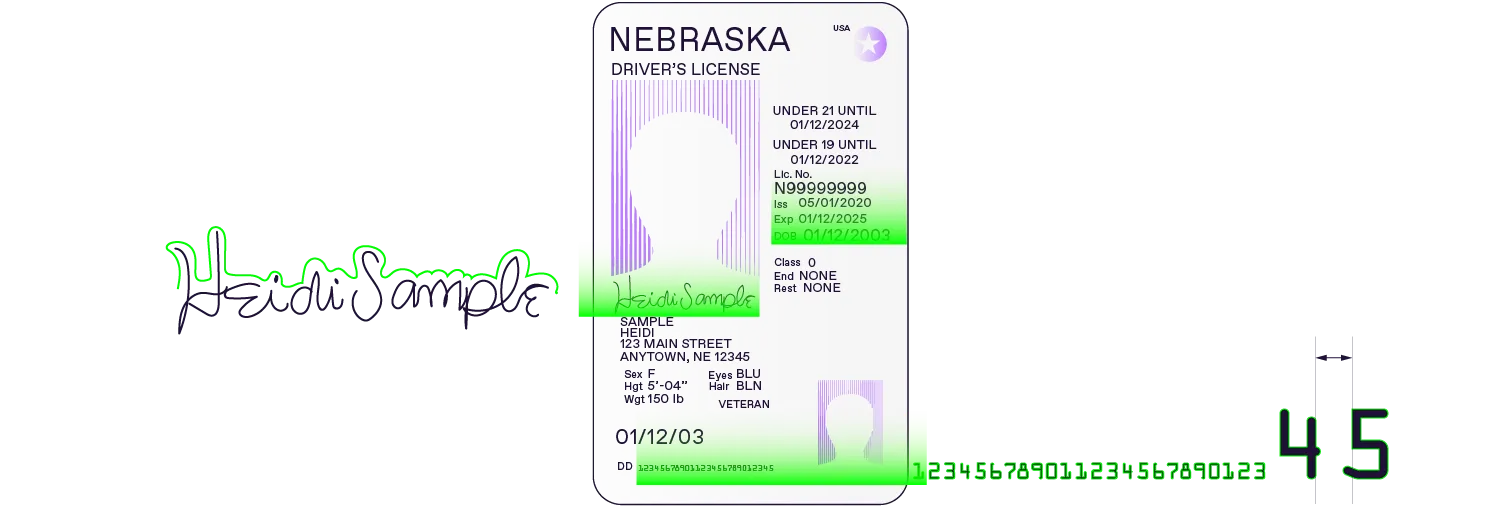
Regula’s OCR validates both document data and fonts
OCR technology knows which data to look for and where to find it through document templates. These templates act as detailed maps of a specific ID, showing every tiny piece of information that can be found in an identity document. By creating templates for every single ID type, identity verification software developers enhance the speed and precision of document checks.
Because identity documents vary by type and issuer, the same data may be presented in different ways. Names, dates, addresses, and document numbers may follow different formats depending on the country, state, or document version. To process the document correctly, OCR needs to know what kind of data to expect in each field and how that data should appear.
Some document fields may also contain coded values. For example, a document may use a number instead of the full name of the issuing authority, or abbreviations such as “GRN” instead of “Green” for eye color. So OCR must be able not only to read the data, but also to interpret it correctly.
The ID data and format is validated against a corresponding document type in an identity document database. The broader and more up-to-date that database is, the more accurately the OCR can read and check document data.
Why is OCR key for identity verification?
OCR is key for identity verification because it provides the data foundation for automated document checks. Before a system can validate document fields, it first needs to extract that data from the ID accurately.
This is especially important in remote identity verification, where document data has to be captured and processed quickly enough for the system to run further checks without falling back on manual review. OCR turns document images into structured data that can move through the rest of the verification flow.
OCR also helps reduce friction for users during onboarding by minimizing manual data entry. Instead of filling out long forms, customers can submit an ID image and let the system capture the necessary data automatically. This matters even more in multi-person onboarding. Entering passport details by hand for a family of five is tedious and easy to get wrong.
What makes OCR reliable for passports, IDs, and driver’s licenses?
Not every OCR engine is designed for identity verification. General-purpose OCR may be able to read text, but identity documents require more than text extraction. To work reliably, OCR needs to understand document structure, recognize data across multiple zones, and validate whether fields appear in the correct format, font, and position for a specific document type.
Since Regula’s OCR is trained specifically for identity documents and supports checks that go beyond text extraction, it is a useful example here.
For instance, OCR used in identity verification should be able to read both the visual zone and machine-readable elements such as the MRZ. It can also process perforated data often found in IDs.
In addition, Regula’s OCR checks whether the data is placed correctly and appears on the document as it should in a genuine ID. This includes checking the vertical and horizontal positions of each line containing personal data. In other words, the technology verifies that the data is printed exactly where it is expected to be.
The OCR also checks whether the MRZ is printed in OCR-B, a monospace font widely used in machine-readable zones across identity documents. This helps detect suspicious alterations or other signs of tampering.
In identity verification, OCR should also work together with lexical analysis. This type of check helps assess whether the personal data on the document is relevant and valid against the corresponding template. For example, if a birth date should appear as DD.MM.YYYY but is printed as MM.DD.YYYY, it’s a potential fraud signal.
Once OCR extracts ID data accurately from several document zones, the system can perform further cross-checks. These checks are important because they help confirm that the same information is consistent across the document. Fraudsters may find it easier to alter visible data than machine-readable elements, so these inconsistencies can help reveal fraud at an early stage.

OCR used for identity verification enables cross-checking data between visual inspection and machine readable zones.
The challenges of OCR in identity verification
OCR in identity verification has to work under far more demanding conditions than OCR used for ordinary documents.
Image quality and document capture
For OCR to work well in identity verification, the document must be in good condition, and it must be properly scanned. Poor printing, wear and tear, blur, glare, low resolution, or a skewed camera angle can all reduce OCR accuracy. That is why many identity verification solutions try to automate image capture and document positioning as much as possible, rather than relying entirely on the user’s photography skills.

Regula’s OCR detects an ID card shot at a skewed angle and automatically repositions it for accurate processing.
Languages, scripts, and local data formats
Another challenge is the sheer variety of languages, scripts, and local data conventions used in identity documents around the world. Non-Latin alphabets and complex scripts, such as Khmer in Cambodian IDs, can make some fields harder to recognize accurately. Dates can also be difficult to interpret when documents use local calendar systems, as in Thai identity documents, where dates may appear in both the Thai and Gregorian calendars.
OCR used for identity verification must be trained not only to read different languages, but also to interpret local naming patterns, date formats, and other document-specific data correctly.
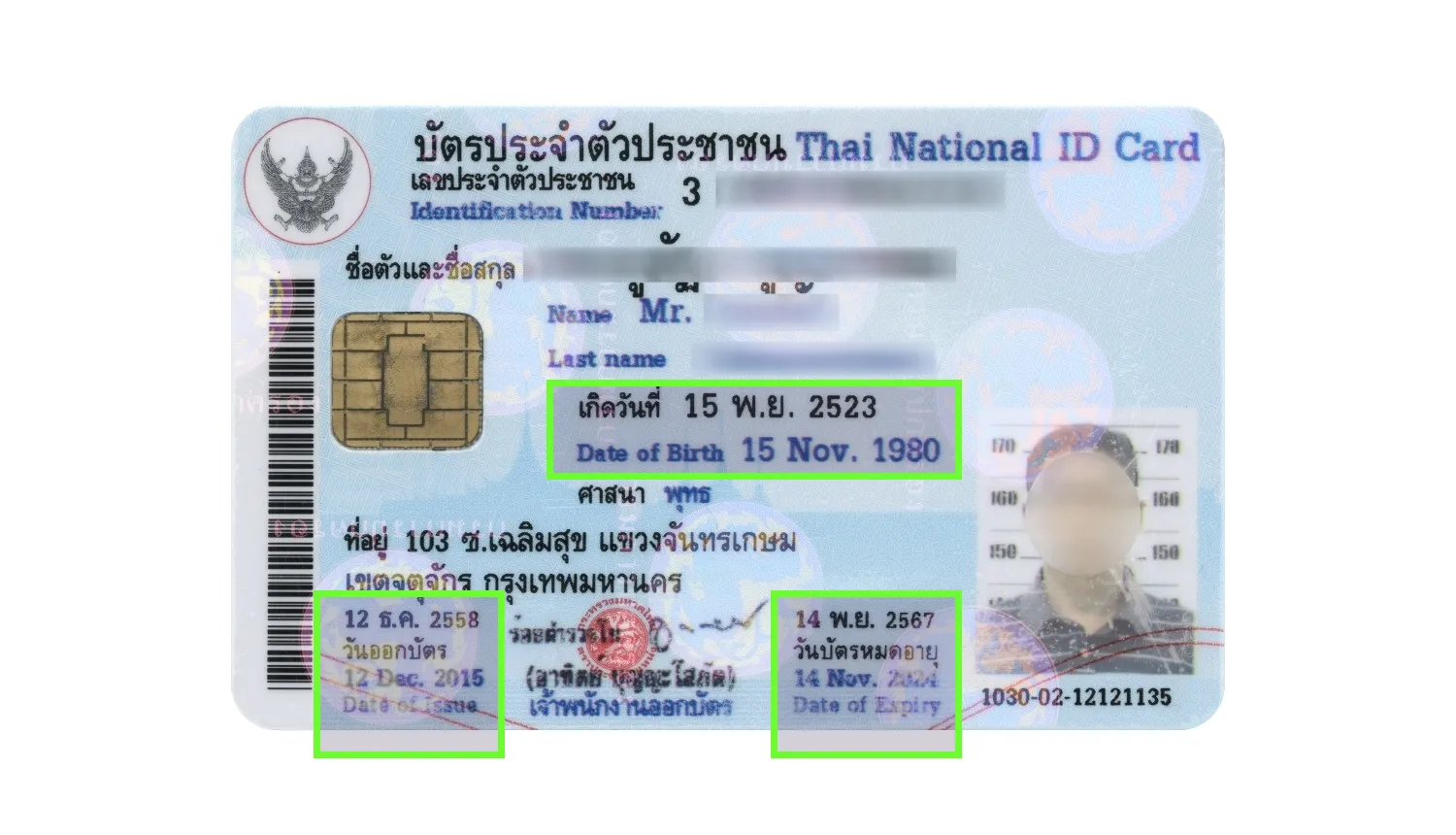
Dates in Thai identity documents are represented in the Thai calendar and duplicated in the Gregorian calendar.
Layout variation across issuers
Layout variation also adds complexity. The same document type can differ not only from country to country, but also across jurisdictions within a single country. Driver’s licenses are a good example: in places such as the United States or Mexico, regional issuers use many different designs. So, OCR should know for sure what document it is processing, and which data should be found in certain fields.

Every Mexican state issues its own driver’s licenses, resulting in at least 32 different document designs and formats.
Backgrounds, security features, and overlapping text
Identity documents also contain design elements that can make OCR harder. Personal data may appear on patterned backgrounds (often in driver’s licenses), overlap with field labels, or be partially interrupted by holograms and other security features. Some documents also use multicolor text or specialized fonts.
These challenges can be handled much more reliably when an identity verification vendor has a broad document database and enough training data to support document-specific OCR.

Bright background patterns can make OCR harder.
Is OCR enough to verify an identity document?
OCR has become one of the core technologies behind automated identity verification. Still, OCR works primarily with the visual zone of a document, and that zone was designed for people, not for machines. Unlike MRZs and barcodes, visual-zone data typically does not include checksums or other built-in control elements that can verify the data has been recognized and read correctly.
That is why OCR cannot be treated as a standalone proof of document authenticity. It becomes much more reliable when supported by document templates, logical and lexical checks, cross-zone comparisons, and other fraud detection technologies.
Regula’s technology is trained on identity documents from 254 countries and territories. It doesn’t approach a passport, ID card, or driver’s license as an unknown image with text on it. It approaches it as a specific document with a known layout, expected fields, local formatting rules, and country-specific design patterns.
That means Regula knows how a genuine document should be read before the check even starts. That is what makes its OCR effective for identity verification.
If your business needs to process identity documents from different countries automatically and reliably, Regula can help. Request a demo to see how it works in practice.



